Чем работать с XML - обзор онлайн-сервисов и xml редакторов. Работаем с LINQ to XML. Инструментальные средства для работы с XML
Цель работы: получить практические навыки обработки данных, представленных в формате Extensible Markup Language (XML ).
Задачи работы:
– изучить технологию описания данных XML ;
– изучить основные классы библиотеки FCL , поддерживающие обработку данных, представленных в формате XM L;
– выполнить практическое задание по разработке приложения на языке С#.
Краткие теоретические сведения
Формат XML – это способ хранения данных, представленных в простом текстовом формате, что означает, что эти данные могут быть прочитаны практически любым компьютером. Данное обстоятельство делает этот формат весьма подходящим для использования при передаче данных через Интернет и допускает даже непосредственное прочтение человеком.
XML является языком разметки, с помощью которого можно описать произвольные данные. На основеэтогоязыка можно организовать хранение информации и ее обмен, не зависящий ни от конкретных приложений, ни от платформы, на которой они исполняются.
XML - документы. Законченный набор данных известен в языке XML под названием XML -документа. XML -документ может представлять собой физический файл на вашем компьютере, а может быть всего лишь строкой в памяти, однако он должен быть законченным и подчиняться определенным правилам. XML -документ состоит из нескольких различных частей, наиболее важными из которых являются XML- элементы, где содержатся те данные, из которых собственно и состоит документ.
Microsoft . NET Framework использует объектную модель данных XML Document Object Model(DOM ), чтобы обеспечить доступ к данным в XML -документах, и дополнительные классы для чтения, записи и навигации в пределах XML -документа. Эти классы поддерживаются пространством имен System.XML . Пример представления описания каталога книг в модели DOM приведен на рис. 8.1.
Описание документа на языке XML включает в себя операторы, написанные с соблюдением требований его синтаксиса. При создании XML -документа вместо использования ограниченного набора определенных элементов имеется возможность создавать собственные элементы и присваивать им любые имена по выбору пользователя. Именно поэтому язык XML является расширяемым (extensible). Следовательно, этот язык можно использовать для описания практически любого документа: от музыкальной партитуры до базы данных.
Katalog
Рис. 8.1. Иерархическая структура документа
Например, каталог книг можно описать так, как показано в листинге 8.1 (номера строк не являются частью документа XML ). Для создания XML -документа в среде Visual Studio . NET следует воспользоваться командой File \ New File и в выпавшем списке шаблонов выбрать имя шаблона XML File .
Листинг 8.1 . Текст XML -документа
В строке 1 данного листинга записано объявление XML , идентифицирующее текст как документ XML .Несмотря на необязательность объявления XML , документ должен включать его в себя для идентификации используемой версии XML , поскольку документ без объявления XML может в дальнейшем рассматриваться как соответствующий последней версии XML, в результате чего могут появиться ошибки. Информационный параметр version указывает версию XML , использованную в документе, параметр encoding – кодировку документа (utf-8 ).
В строке2 записан комментарий, начинающийся с символов . Комментарии можно размещать по всему XML -документу.
В XML -документе данные маркируются с помощью тэгов (элементов ), представляющих собой имена, заключенные в угловые скобки (< > ). Имена тэгов в XML -документе (такие как KATALOG , BOOK , TITLE , AUTHOR ,PAGES ,PRICE , PDATA в листинге 8.1) не являются определениями языка XMLи назначаются при создании документа. Для тэгов можно выбирать любые корректно заданные имена, например INVENTORY вместо KATALOG либо ITEM вместо BOOK . В строке 3 записан корневой тэг – KATALOG , открывающий разметку всего документа. При завершении написания корневого тэга среда автоматически вставляет конечный тэг (строка 18 листинга 8.1), отмечая его символами .
Примечание . Попытка создания более одного корневого элемента в XML -документе является ошибкой.
Внутри корневого элемента может находиться произвольное количество вложенных элементов. В листинге 8.1 XML -документ имеет иерархическую структуру в виде дерева с элементами, вложенными в другие элементы, и с одним элементом верхнего уровня элемент Документ , или Корневой элемент (в нашем примере – KATALOG ), который содержит все другие элементы. Корневой элемент KATALOG включает в себя элементы-потомки BOOK . В свою очередь элемент BOOK состоит из элементов-потомков TITLE , AUTHOR ,PAGES ,PRICE , PDATA .
Корректно сформированные XML-документы. Документ называется корректно сформированным (well-formed), если он соответствует следующему минимальному набору правил для XML -доку-ментов:
– XML -документ должен иметь только один корневой элемент – элемент Документ . Все другие элементы должны быть вложены в корневой элемент;
– элементы должны быть вложены упорядоченным образом. Если элемент начинается внутри другого элемента, то он должен и заканчиваться внутри этого элемента;
– каждый элемент должен иметь начальный и конечный тэги. В отличие от языка HTML, в языке XML не разрешается опускать конечный тэг даже в том случае, когда браузер в состоянии определить, где заканчивается элемент;
– название элемента в начальном тэге должно точно соответствовать (с учетом регистра) названию в соответствующем конечном тэге;
– название элемента должно начинаться с буквы или с символа подчеркивания (_ ), после чего могут идти буквы, цифры, а также символы: точка (. ), тире (- ) или подчеркивание.
Это базовые правила корректного формирования XML -документа. Для других понятий языка XML (атрибутов, примитивов, связей) действуют свои правила, которые необходимо соблюдать. Можно сказать, что если документ создан правильно и при его отображении и использовании не возникает никаких ошибок, то это и есть корректно сформированный документ. Если вы ошибетесь в каком-либо тэге HTML -страницы, то браузер просто проигнорирует соответствующий тэг, а ошибка в тэге XML -страницы сделает невозможным ее отображение. При наличии одной из ошибок встроенный в Internet Explorer анализатор (его иногда называют XML -про-цессором, или парсером) определяет ее позицию
Классы библиотеки FCL для чтения XML-файлов. Работу с XML -документами поддерживают следующие классы библиотеки FCL : XmlTextReader , XmlDocument , XPathNavigator .
Класс XmlTextReader – это абстрактный класс, выполняющий чтение и обеспечивающий быструю доставку некэшированных данных.Этот подход в отношении серверных ресурсов является наименее дорогостоящим, но он принуждает извлекать данные последовательно, от начала до конца.
КлассXmlDocument представляет собой реализацию модели DOM . Этот класс удерживает данные в памяти после вызова метода Load () для извлечения их из файла или потока, обеспечивает древовидное представление документа в памяти с возможностями навигации и редактирования, а также позволяет модифицировать данные и сохранять их обратно в файл.
КлассXPathNavigator так же, как и класс XmlDocument , удерживает в памяти XML - документ целиком. Он предоставляет расширенные средства поиска данных, однако не обеспечивает возможности внесения изменений и их сохранения.
Класс XmlTextReader . Рассмотрим простой пример. Разместим на форме элементы richTextBox и button (рис. 8.2). При щелчке на кнопку в элемент richTextBox будет загружаться файл, содержимое которого было представлено в листинге 8.1. Код функции, вызываемой при щелчке на кнопку, показан в листинге 8.2.

Рис. 8.2. Результаты считывания из Xml -документа
Листинг 8.2 . Код обработчика щелчка по кнопке
//Очистка элемента richTextBox 1
richTextBox 1. Clear ();
// Вызов статического метода Create () , возвращающего объект класса
// Файл book.xml находится в том же месте, что и исполняемый файл
// программы
// Метод Read () перемещает на следующий узел Xml -документа
while (rdr.Read())
if (rdr.NodeType == XmlNodeType .Text)
richTextBox1.AppendText(rdr.Value + "\r\n");
Класс XmlReader также может читать данные со строгим контролем типов. Существует несколько методов ReadElementContentAs , выполняющих чтение, среди которых ReadElementContentAsDecimal() ,ReadElementContentAs Int () , ReadElementContentAs Boolean () и др.
В листинге 8.3 показано, как считывать значения в десятичном формате и выполнять над ними математические операции. В рассматриваемом случае цена элемента увеличивается на 25 %. Результаты выполнения этого кода показаны на рис. 8.3.

Рис. 8.3. Результаты считывания из Xml- документа
только названия и цены книг
Листинг 8.3 . Чтение данных со строгим контролем типов
// Очистка элемента richTextBox 1
richTextBox 1. Clear ();
// Создание потока для чтения из файла book . xml
XmlReader rdr = XmlReader.Create("book.xml");
while (rdr.Read())
if (rdr.NodeType == XmlNodeType.Element)
// Проверка имени элемента
if (rdr . Name == " PRICE ")
// Метод ReadElementContentAsDecimal () выполняет
// преобразование содержимого элемента к типу decimal
decimal price = rdr.ReadElementContentAsDecimal();
richTextBox1.AppendText(" Текущая цена = " + price +
"руб\ r \ n ");
// Изменение цены на 25 %
price += price * (decimal).25;
richTextBox1.AppendText(" Новая цена = " + price +
" руб \r\n\r\n");
else if (rdr.Name == "TITLE")
richTextBox1.AppendText(rdr.ReadElementContentAsString() + "\r\n");
Класс XmlDocument. Этот класс и производный от него класс XmlDataDocument используются в библиотеке .NET для представления объектной модели документа DOM .
В отличие от класса XmlReader , класс XmlDocument предла-гает возможности не только чтения, но и записи, а также произвольного доступа к дереву DOM .
Рассмотрим пример, в котором создается объект класса XmlDocument , загружается документ с диска и отображается окно списка с названиями книг (рис. 8.4).

Рис. 8.4. Отображение названий книг в списке.
В классе формы приложения создадим объект класса XmlDocument :
XmlDocument _doc = new XmlDocument();
Код обработчика щелчка по кнопке приведен в листинге 8.4.
_doc.Load("book.xml");
// Получить только те узлы, которые нужны
XmlNodeList nodeLst = _ doc . GetElementsByTagName (" TITLE ");
// Просмотр в цикле класса XmlNodeList
foreach (XmlNode node in nodeLst )
listBox 1. Items . Add (node . InnerText );
Введем в приложение возможность вывода свдений о книге, наз-вание которой выделено в списке, для чего добавим обработчик события listBox 1_ SelectedIndexChanged так, как показано в листинге 8.5.
Листинг 8.5 . Обработчик щелчка по элементу списка
private void listBox1_SelectedIndexChanged(object sender, EventArgs e)
// Создание строки поиска
string srch = "KATALOG/BOOK";
// Поиск дополнительных данных
XmlNode foundNode = _doc.SelectSingleNode(srch);
if (foundNode != null)
MessageBox.Show(foundNode.OuterXml);
MessageBox.Show("Not found");
Результаты работы приложения показаны на рис. 8.5.

Рис. 8.5. Вывод сведений о выделенном элементе списка
С помощью класса XmlDocument такжеможно вставлять узлы в существующий документ, для чего используется метод Create - Element () .
Например, для создания нового элемента BOOK необходимо записать следующий код:
XmlElement newBook = _doc.CreateElement("BOOK");
Создать элементы, вложенные в элемент BOOK , можно с помощью следующего кода:
// Создание нового элемента AUTOR
XmlElement newAuthor = _doc.CreateElement("AUTOR");
newAuthor.InnerText = "C. Байдачный ";
Полный код обработчика щелчка по кнопке приведен в лис-тинге 8.6, результаты его работы показаны на рис. 8.6.
Листинг 8.6 . Обработчик щелчка по кнопке
private void button 1_ Click (object sender , EventArgs e )
_doc.Load("book.xml");
XmlElement newBook = _doc.CreateElement("BOOK");
// Создание нового элемента TITLE
XmlElement newTitle = _doc.CreateElement("TITLE");
newTitle.InnerText = ".NET Framework 2.0";
newBook.AppendChild(newTitle);
// Создание нового элемента AUTOR
XmlElement newAuthor = _doc.CreateElement("AUTOR");
newAuthor.InnerText = "C. Байдачный ";
newBook.AppendChild(newAuthor);
// Создание нового элемента PAGES
XmlElement newpages = _doc.CreateElement("PAGES");
newpages.InnerText = "498";
newBook.AppendChild(newpages);
// Создание нового элемента PRICE
XmlElement newprice = _doc.CreateElement("PRICE");
newprice.InnerText = "590";
newBook.AppendChild(newprice);
// Создание нового элемента PDATA
XmlElement newpdata = _doc.CreateElement("PDATA");
newpdata.InnerText = "2006";
newBook.AppendChild(newpdata);
// Добавление в текущий документ
_doc.DocumentElement.AppendChild(newBook);
// Запись документа на диск
XmlTextWriter tr = new XmlTextWriter("bookEdit.xml", null);
tr.Formatting = Formatting.Indented;
_doc.WriteContentTo(tr);
tr . Close ();
XmlNodeList nodeLst = _ doc . GetElementsByTagName (" TITLE ");
// Просмотр в цикле класса XmlNodeList
foreach (XmlNode node in nodeLst )
listBox 1. Items . Add (node . InnerText );
При использовании классовXmlDocument иXmlReader необходимо учитывать следующие особенности. Если требуется возможность произвольного доступа к документу, то следует применять класс XmlDocument , а если нужна потоковая модель, то классы, основанные на классе XmlReader . Класс XmlDocument отличается большой гибкостью, но его требования к памяти являются более высокими, чем у классаXmlReader , а производительность при считывании документа – более низкой.

Рис. 8.6. Окно работающего приложения
с добавленным узлом
Класс XPathNavigator . КлассXPathNavigator является частью пространства имен System . Xml . XPath , созданного для увеличения быстродействия. Это пространство обеспечивает только чтение документов, следовательно средства редактирования в нем отсутствуют, а классы построены так, чтобы обеспечить быстрое выполнение на заданном XML -документе циклов и операций выбора в стиле курсора.
Наилучшим способом использования классов из пространства имен System . Xml . XPath является просмотр документа book . xml в цикле.
Разместим на форме элементы listBox и button . Код обра-ботчика щелчка по кнопке приведен в листинге 8.7, результаты выполнения этого кода – на рис. 8.7.
Листинг 8.7 . Обработчик щелчка по кнопке
private void button 1_ Click (object sender , EventArgs e )
// Создание объекта с именем doc класса XPathDocument и передача
// в его конструктор имени XML - файла book.xml
XPathDocument doc = new XPathDocument("book.xml");
// Создание объекта с именем nav класса XPathNavigator на базе объекта
// XPathDocument. Объект nav может использоваться только для чтения
XPathNavigator nav = ((IXPathNavigable)doc). CreateNavigator();
// Создание объекта XPathNodeIterator для узлов каталога
// и его дочерних узлов
XPathNodeIterator iter = nav.Select("/KATALOG/BOOK");
while (iter.MoveNext())
// Метод SelectDescendants() класса XPathNavigator выбирает все
// узлы-потомки текущего узла, соответствующие условиям выбора
XPathNodeIterator newIter =
В первой статье в блоге .NET «Работаем с XML » в комментариях народ потребовал статьи LINQ to XML. Что же, попробуем раскрыть принципы работы этой новой технологии от Microsoft.
Создадим базу для ведения каталога аудиозаписей. База будет состоять из треков:
- Название
- Исполнитель
- Альбом
- Продолжительность
Для начала создадим консольное приложение (я пишу свои проекты на C#, но суть в общем-то понятна будет всем) и подключим необходимое пространство имен
Using System.Xml.Linq;
Создание файлов XML
Создадим XML файл нашей базы содержащий несколько тестовых записей уже при помощи LINQ:
//задаем путь к нашему рабочему файлу XML string fileName = "base.xml"; //счетчик для номера композиции int trackId = 1; //Создание вложенными конструкторами. XDocument doc = new XDocument(new XElement("library", new XElement("track", new XAttribute("id", trackId++), new XAttribute("genre", "Rap"), new XAttribute("time", "3:24"), new XElement("name", "Who We Be RMX (feat. 2Pac)"), new XElement("artist", "DMX"), new XElement("album", "")), new XElement("track", new XAttribute("id", trackId++), new XAttribute("genre", "Rap"), new XAttribute("time", "5:06"), new XElement("name", "Angel (ft. Regina Bell)"), new XElement("artist", "DMX"), new XElement("album", "...And Then There Was X")), new XElement("track", new XAttribute("id", trackId++), new XAttribute("genre", "Break Beat"), new XAttribute("time", "6:16"), new XElement("name", "Dreaming Your Dreams"), new XElement("artist", "Hybrid"), new XElement("album", "Wide Angle")), new XElement("track", new XAttribute("id", trackId++), new XAttribute("genre", "Break Beat"), new XAttribute("time", "9:38"), new XElement("name", "Finished Symphony"), new XElement("artist", "Hybrid"), new XElement("album", "Wide Angle")))); //сохраняем наш документ doc.Save(fileName);
Теперь в папке с нашей программой после запуска появится XML файл следующего содержания:
Для создания подобного файла средствами XmlDocument кода понадобилось где-то раза в 2 больше. В коде выше мы воспользовались конструктором класса XDocument, который принимает в качестве параметра перечень дочерних элементов, которыми мы изначально хотим инициализировать документ. Используемый конструктор XElement принимает в качестве параметра имя элемента, который мы создаем, а так же перечень инициализирующих элементов. Удобно то, что мы в этих элементах можем задавать как новые XElement, так и XAttribute. Последние отрендретятся в наш файл как атрибуты самостоятельно. Если вам не нравится использоваться такую вложенность конструкторов и вы считаете такой код громоздким, то можно переписать в более традиционный вариант. Код ниже даст на выходе аналогичный XML файл:
XDocument doc = new XDocument();
XElement library = new XElement("library");
doc.Add(library);
//создаем элемент "track"
XElement track = new XElement("track");
//добавляем необходимые атрибуты
track.Add(new XAttribute("id", 1));
track.Add(new XAttribute("genre", "Rap"));
track.Add(new XAttribute("time", "3:24"));
//создаем элемент "name"
XElement name = new XElement("name");
name.Value = "Who We Be RMX (feat. 2Pac)";
track.Add(name);
//создаем элемент "artist"
XElement artist = new XElement("artist");
artist.Value = "DMX";
track.Add(artist);
//Для разнообразия распарсим элемент "album"
string albumData = "
Естественно выбирать необходимый способ нужно по ситуации.
Чтение данных из файла
//задаем путь к нашему рабочему файлу XML string fileName = "base.xml"; //читаем данные из файла XDocument doc = XDocument.Load(fileName); //проходим по каждому элементу в найшей library //(этот элемент сразу доступен через свойство doc.Root) foreach (XElement el in doc.Root.Elements()) { //Выводим имя элемента и значение аттрибута id Console.WriteLine("{0} {1}", el.Name, el.Attribute("id").Value); Console.WriteLine(" Attributes:"); //выводим в цикле все аттрибуты, заодно смотрим как они себя преобразуют в строку foreach (XAttribute attr in el.Attributes()) Console.WriteLine(" {0}", attr); Console.WriteLine(" Elements:"); //выводим в цикле названия всех дочерних элементов и их значения foreach (XElement element in el.Elements()) Console.WriteLine(" {0}: {1}", element.Name, element.Value); }
Здесь в коде, думаю, ничего сложного нету и приведены комментарии. После запуска нашей программый в консоли отобразится следующий результат:
Track 1 Attributes: id="1" genre="Rap" time="3:24" Elements: name: Who We Be RMX (feat. 2Pac) artist: DMX album: The Dogz Mixtape: Who"s Next?! track 2 Attributes: id="2" genre="Rap" time="5:06" Elements: name: Angel (ft. Regina Bell) artist: DMX album: ...And Then There Was X track 3 Attributes: id="3" genre="Break Beat" time="6:16" Elements: name: Dreaming Your Dreams artist: Hybrid album: Wide Angle track 4 Attributes: id="4" genre="Break Beat" time="9:38" Elements: name: Finished Symphony artist: Hybrid album: Wide Angle
Изменение данных
Попробуем пройтись по всем узлам library и увеличить аттрибут Id элемента track на 1.
(дальше писать объявление пути к файлу и результат вывода в консоль я приводить не буду, чтобы не перегружать лишней информацией статью, все компилировал, все работает:))
:
//Получаем первый дочерний узел из library XNode node = doc.Root.FirstNode; while (node != null) { //проверяем, что текущий узел - это элемент if (node.NodeType == System.Xml.XmlNodeType.Element) { XElement el = (XElement)node; //получаем значение аттрибута id и преобразуем его в Int32 int id = Int32.Parse(el.Attribute("id").Value); //увеличиваем счетчик на единицу и присваиваем значение обратно id++; el.Attribute("id").Value = id.ToString(); } //переходим к следующему узлу node = node.NextNode; } doc.Save(fileName);
Теперь попробуем это сделать более правильным способом для наших задач:
Foreach (XElement el in doc.Root.Elements("track")) { int id = Int32.Parse(el.Attribute("id").Value); el.SetAttributeValue("id", --id); } doc.Save(fileName);
Как видим – этот способ нам подошел больше.
Добавление новой записи
Добавим новый трек в нашу библиотеку, а заодно вычислим средствами LINQ следующий уникальный Id для трека:
Int maxId = doc.Root.Elements("track").Max(t => Int32.Parse(t.Attribute("id").Value)); XElement track = new XElement("track", new XAttribute("id", ++maxId), new XAttribute("genre", "Break Beat"), new XAttribute("time", "5:35"), new XElement("name", "Higher Than A Skyscraper"), new XElement("artist", "Hybrid"), new XElement("album", "Morning Sci-Fi")); doc.Root.Add(track); doc.Save(fileName);
Вот таким подним запросом ко всем элементам вычисляется максимальное значение аттрибута id у треков. При добавлении полученное максимальное значение инкрементируем. Само же добавление элемента сводится к вызову метода Add. Обратите внимание, что добавляем элементы в Root, так как иначе нарушим структуру XML документа, объявив там 2 корневых элемента. Так же не забывайте сохранять ваш документ на диск, так как до момента сохранения никакие изменения в нашем XDocument не отразятся в XML файле.
Удаление элементов
Попробуем удалить все элементы исполнителя DMX:
IEnumerable
В этом примере мы вначале выбрали все треки у который дочерний элемент artst удовлетворяет критерии, а потом в цикле удалили эти элементы. Важен вызов в конце выборки ToList(). Этим самым мы фиксируем в отдельном участке памяти все элементы, которые хотим удалить. Если же мы надумаем удалять из набора записей, по которому проходим непосредственно в цикле, мы получим удаление первого элемента и последующий NullReferenceException. Так что важно помнить об этом.
По совету xaoccps удалять можно и более простым способом:
IEnumerable
В этом случае приводить к списку наш полученный результат вызовом функции ToList() не нужно. Почему этот способ не использовал изначально описал в
Работа с данными в формате XML в приложениях ASP.NET 2.0, объект XmlDataDocument и элемент управления XML
Этот модуль посвящен тому, как можно работать с данными в формате XML из приложений ASP.NET.
XML расшифровывается как Extensible Markup Language (расширяемый язык разметки), хотя сам XML - это не язык. XML - набор правил, используемых для создания своих языков разметки. Например, представим себе, что у нас существуют такие данные о сотруднике:
Эти данные, конечно, можно представить как угодно: в виде таблицы в реляционной базе данных, в виде таблицы Excel или HTML, в виде таблицы в документе Word или в виде текстового документа ASCII, в виде файла *.csv и т.п. Если мы представим их в формате придуманного нами XML-совместимого языка разметки ABML (Address Book Markup Language), то они будут выглядеть так:
Немного о том, как расшифровать этот код. Первые две строки - это пролог (использовать его, в принципе, необязательно, но очень рекомендуется). Строка
называется объявлением XML (XML Declaration) и говорит о том, что этот файл соответствует спецификации XML 1.0, принятой в качестве рекомендации World Wide Web Consortium 10 февраля 1998 года. Строка
называется определением типа документа (Document Type Definition) и говорит о том, что структура языка, которому соответствует этот документ, описана в файле abml.dtd (можно использовать и внутренние DTD, когда описание языка находится прямо в документе). Сейчас для описания структуры XML-совместимых языков чаще используются не DTD, а XML Schema - к ним проще обращаться и они обеспечивают больше возможностей, в частности, при описании различных типов данных. Эта же строка с использованием XML Schema может выглядеть так:
в зависимости от того, где лежит сама Schema - описание данного языка - в файле abml.xml или на Web-сервере (корпоративное хранилище схем от Microsoft - BizTalk Server).
Пример XML Schema для нашего языка может выглядеть так:
XML – это формализованный набор правил для «разметки» документа – то есть выделения его логической структуры. То, что находится внутри любого документа, совместимого с форматом XML, можно разбить на две категории: разметку и само содержание. Вся информация о разметки должна начинаться либо с символа амперсанда (&), либо с символа левой угловой скобки (<). В XML существует шесть типов информации разметки: элементы, атрибуты, комментарии, инструкции обработки, ссылки на сущности и разделы CDATA.
· Элементы (elements) – это наиболее распространенный тип информации о разметке. Элемент выделяет логическую составную часть документа. Обычный документ состоит из открывающих и закрывающих тегов, которые могут окружать содержимое, другой элемент, или и то, и другое вместе. Теги с названиями элемента заключаются в угловые скобки. Вот пример элемента:
· Атрибуты (attributes) состоят из пары имя атрибута/значение атрибута и применяются к элементам. Атрибуты положено помещать после имени элемента в открывающем теге. Например, атрибутами являются ширина и высота:
· Комментарии (comments) – это любой текст, который будет игнорироваться процессором XML. Пример:
· Инструкции обработки (processing instructions) используются для передачи информации приложению, обрабатывающему документ XML. Синтаксис инструкции обработки выглядит так:
· Ссылки на сущности (entity references) используются для того, чтобы помещать в документ зарезервированные символы или зарезервированные слова. К примеру, нам надо вставить в документ левую угловую скобку (<), которая является зарезервированным символом XML. Просто так вставить в текст документа мы ее не сможем: приложение, работающее с документом, решит, что она относится к разметке. Поэтому нам необходимо использовать сочетание символов <. lt означает less than (меньше чем), а амперсанд (&) и точка с запятой (;) выделяют ссылку на сущность.
· Раздел CDATA (CDATA section) – это часть текста, которая не обрабатывается, как остальные части документа XML, а передаваться приложению напрямую. Это средство может пригодиться, например, при передаче приложению какого-либо кода.
Синтаксические принципы XML:
· Документы XML состоят из символов Unicode (Unicode – это 16-битный набор символов, который позволяет отображать документы на любых языках).
· XML чувствителен к регистру. Теги и в нем – это разные теги.
· Пустое пространство (whitespace) – это невидимые символы, такие, как пробел (ASCII 32), символ табуляции (ASCII 9), символы возврата каретки (ASCII 13) и символы перевода строки (ASCII 10). Пустое пространство игнорируется внутри тегов, но сохраняется в символьных данных (то есть между открывающим и закрывающим тегами). Пустое пространство в символьных данных передается обрабатывающему приложению.
· Многие компоненты XML должны иметь имена (наиболее наглядный пример – элементы и атрибуты). Правила именования XML выглядят следующим образом: имя XML должно начинаться с буквы или подчеркивания, за которым следует любое количество букв, цифр, дефисов, подчеркиваний или точек, например:
Мой_Уникальный_Идентификатор_Тега-123 2_Это_имя_является_неверным
· Имя компонента XML не может начинаться с символов xml (как в верхнем, так и в нижнем регистре). Такие имена зарезервированы создателями спецификации для служебных целей.
· Символьные значения должны быть помещены в одинарные или двойные кавычки.
· В XML должен строго соблюдаться порядок вложенности тегов.
· Любому открывающему тегу в XML должен соответствовать закрывающий тег.
· Пустой тег в XML записывается как открывающий тег, перед правой угловой скобкой в котором стоит прямой слеш (/).
· В документе XML может быть только один корневой элемент.
В чем преимущества размещения данных в XML перед традиционными двоичными форматами? Почему в настоящее время большинство крупных производителей программного обеспечения либо уже полностью перешли на работу с данными в XML-совместимом формате (например, Micrоsoft Office 2003), либо планируют перейти в ближайшем будущем? Главная причина - данные в XML очень легко передавать между самыми разными приложениями и их очень легко преобразовывать. Дополнительные моменты, связанные с преимуществами XML:
- Независимый формат данных - данные в формате XML можно открывать в любом XML-совместимом (точнее, совместимым с конкретной схемой) приложении. Пример: на любом предприятии документы хранятся в самых разных форматах - форматах разных версий Word, текстовых, HTML, PDF и т.п. Проблем из-за этого возникает очень много, радикально решаются при помощи XML.
- Общий принцип - один источник данных (документ XML), много представлений. Наглядно можно продемонстрировать на примере Web-сайта, к которому нужно обращаться из разных броузеров и через WAP.
- Гораздо более простая передача данных "сквозь" приложения. Примеры - прохождение документов через цепочку поставщиков, или прохождение данных между разнородными программными продуктами на одном предприятии (что необходимо очень часто).
- Улучшенные возможности поиска данных. Во-первых, нет необходимости обращаться к документам разных двоичных форматов, во-вторых, иерархическая структура документов XML облегчает поиск.
- Более простая разработка приложений - нет необходимости реализовывать в приложениях поддержку большого количества разных двоичных форматов данных.
- Данные в текстовом формате (стандарт XML - Unicode) проще, чем двоичные, хранить на различных платформах и безопаснее (с точки зрения отсутствия вредоносного двоичного кода) передавать в сетях. Целое направление в разработке приложений - XML Web-службы.
Well -formed XML - такой код XML , который соответствует требованиям синтаксиса этого языка (например, каждому открывающему тегу соответствует закрывающий тег). Valid XML - корректный с точки зрения логической структуры этого языка (например, элементы правильно вложены друг в друга), определенной в DTD или XML Schema .
Немного по терминологии XML, которая будет использоваться в этом курсе:
·
XSD
- XML
Schema
Definition
, обычно используемое в VS
.NET
описание структуры документа XML. Обычно она размещается в файлах с расширением *.xsd. Внутри схемы используются специальные теги
xmlns:od="urn:schemas-microsoft-com:officedata">
Чтобы внутри схемы определить строковый элемент Last Name, который может встречаться в документе 0 или больше раз, можно, например, использовать следующий тег:
type="string">
· для описания преобразований XML -совместимых документов используются документы на специальном языке программирования XSLT (eXtensible Stylesheet Language Transform). Сам этот язык, конечно, также является XML -совместимым. В XSLT используется три типа документов:
o документ-источник (source document). Этот документ XML "подается на вход" для преобразования. В нашем случае этот может быть такой документ:
xml-stylesheet type="text/xsl" href="Employees1.xsl "?>
o документ таблицы стилей XSLT (XSLT style sheet document) - XML-совместимый документ, в котором описываются правила проведения трансформаций. В нашем случае пример этого документа может быть таким:
xmlns:xsl="http://www.w3.org/1999/XSL/Transform "
version="1.0 ">
o документ - результат преобразований. Например, при применении нашего преобразования имя сотрудника будет помечено красным, а его должность - синим.
· XPath - специальный язык, который можно использовать для навигации по дереву элементов XML . При использовании объектной модели XPath документ XML представляется в виде дерева узлов. Информация содержится в свойствах этих узлов.
· DOM (Document Object Model ) - представление дерева документа XML в оперативной памяти. DOM позволяет выполнять навигацию по документу XML и редактировать его. Стандартные свойства, методы и события DOM определены в документе, принятом W3C. В ASP.NET при помощи DOM можно создать документ XML и отправить его в броузер пользователю. Другой вариант - клиентский скрипт создает при помощи DOM документ XML на клиенте и передает его на Web-сервер.
· XQuery - это специализированный язык запросов к информации, которая хранится в документах XML . Работа XQuery во многом основана на XPath.
Надо сказать, что XML - это стандартный формат для работы с данными в ADO.NET. Про формат XML и как его можно использовать с DataSet - ниже.
Возможности использования XML при работе с DataSet такие:
· DataSet могут сериализовать данные в формате XML. Схема DataSet (включая таблицы, столбцы, типы данных и ограничения) определяется при этом в XML Schema (файл.xsd ).
· обмен данными из DataSet с удаленными клиентами предписывается производить в формате XML;
· XML можно использовать для синхронизации и преобразования данных в DataSet.
Еще немного про взаимодействие XML и DataSet:
· можно не только создавать XML Schema на основе DataSet (о чем говорилось выше, это делается при помощи метода WriteXmlSchema ), но и наоборот - генерировать DataSet на основе информации их XML Schema (для этого - метод ReadXmlSchema ). Есть возможность сгенерировать DataSet даже без схемы - просто на основе документа XML. Для этой цели предназначен метод InferXmlSchema.
· для объекта DataSet предусмотрен метод ReadXML , который позволяет считать текстовый документ XML (поток текстовых данных XML ) в DataSet . Другой метод, WriteXML , позволяет сохранять содержимое DataSet в XML-совместимом формате. Такая возможность позволяет очень просто организовывать обмен данными между различными приложениями и платформами.
· вы можете создать представление XML (объект XmlDataDocument ) на основе информации из DataSet . Получается, что с информацией в DataSet можно работать двумя способами: обычными реляционными (с самим DataSet) и XML-методами. Оба представления автоматически синхронизируются (при внесении изменений через любое представление).
· вы можете применять преобразования XSLT к данным, которые хранятся в DataSet .
Теперь - о том, как все это выглядит на практике.
Dim ds As New DataSet()
ds.ReadXml(Server.MapPath("filename.xml"))
Метод MapPath для специального объекта Server позволяет преобразовать виртуальный путь к файлу в Web-приложении в физический путь.
Будет ли сгенерирована структура DataSet автоматически из файла XML или она останется прежней, зависит от того, была ли она уже сформирована в этом DataSet и от того, был ли указан необязательный параметр метода ReadXml XmlReadMode.
Dim ds As New DataSet()
Dim da As New SqlDataAdapter(_
"select * from Authors", conn)
da.Fill(ds)
ds.WriteXml(Server.MapPath("filename.xml"))
Есть еще два метода, которые позволяют получить из DataSet данные в формате XML и положить их в строковую переменную. Это методы GetXml и GetXmlSchema. Пример может выглядеть так:
Dim strXmlDS As String = ds . GetXml ()
В DataSet часто помещаются объекты DataTable , связанные между собой отношениями DataRelation (то есть таблицы с Primary и Foreign key). При экспорте в XML информация из родительской таблицы может быть дополнена информацией из подчиненной таблицы. Записи из подчиненной таблицы будут выглядеть как вложенные элементы для записей из главной. Чтобы реализовать такую возможность, необходимо для объекта DataRelation в DataSet для свойства Nested установить значение True (по умолчанию False).
предположим, мы просто экспортируем данные без использования этого свойства:
Dim ds As New DataSet()
’fill the DataSet
...
Dim parentCol As DataColumn = _
ds.Tables("Publishers").Columns("pub_id")
Dim childCol As DataColumn = _
ds.Tables("Titles").Columns("pub_id")
ds.Relations.Add(dr)
ds.WriteXml(Server.MapPath("PubTitlesNotNested.xml"), _
XmlWriteMode.IgnoreSchema)
Код XML получается такой:
а теперь используем устанавливаем свойство Nested для объекта DataRelation в True:
Dim dr As New DataRelation _
("TitlePublishers", parentCol, childCol)
dr.Nested = True
ds.Relations.Add(dr)
ds.WriteXML(Server.MapPath("PubTitlesNested.xml"), _
XmlWriteMode . IgnoreSchema )
Код XML получается уже совсем другой. В каждый элемент типа Pub вложены элементы Titles, выпущенные этим издательством:
XmlDataDocument - это XML -представление данных в DataSet в оперативной памяти. XmlDataDocument неразрывно связан с DataSet . Любые изменения, внесенные в XmlDataDocument , немедленно отражаются в DataSet и наоборот. Ниже будет рассказано о приемах работы с XmlDataDocument.
DataSet - это реляционное представление данных, а XmlDataDocument - иерархическое. Применение XmlDataDocument очень удобно, поскольку работать с данными в формате XML только через DataSet бывает сложно. Например, если загрузить данные из файла XML в DataSet, а затем выгрузить обратно, то вполне может получиться так, что файл будет неузнаваем: будет потеряно форматирование, вполне возможно - порядок элементов, возможно, элементы, которые были проигнорированы из-за несоответствия со схемой, определенной для DataSet.
В XmlDataDocument можно положить документ XML напрямую, а можно создать его на основе DataSet. Код для первого варианта может выглядеть так:
Dim objXmlDataDoc As New XmlDataDocument()
objXmlDataDoc.Load(Server.MapPath("file.xml"))
или так:
objXmlDataDoc.DataSet.ReadXml(Server.MapPath("file.xml"))
Разницы никакой не будет.
А можно вначале создать DataSet, заполнить его данными, а затем на основе его создать XmlDataDocument:
Dim ds As New DataSet()
’fill in ds
...
Dim objXmlDataDoc As New XmlDataDocument(ds)
После того, как объект XmlDataDocument создан, с ним можно выполнять различные действия:
· привязывать к DataGrid и другим элементам управления:
dg.DataSource = objXmlDataDoc.DataSet
· получать нужную строку (она возвращается в виде объекта XmlElement):
Dim elem As XmlElement
elem = objXmlDataDoc.GetElementFromRow _
(ds.Tables(0).Rows(1))
· использовать полный набор свойств и методов DOM. Эти свойства и методы XmlDataDocument наследует от объекта XmlDocument
· применять преобразования XSLT (для этой цели используются объекты XslTransform ).
Подробнее о преобразованиях средствами XSLT:
XSLT позволяет преобразовать исходный документ XML в другой документ, отличающийся по формату и структуре. Например, при помощи XSLT документ XML можно преобразовать к код HTML для отображения в Web-приложении. В ASP.NET для выполнения преобразований XSLT используется класс XslTransform .
Как выглядит работа с ним?
· для проведения преобразований вначале нужно создать DataSet и соответствующий ему XmlDataDocument :
Dim ds As New DataSet()
’fill in DataSet
...
Dim xmlDoc As New XmlDataDocument(ds)
· следующее действие - создаем объект XslTransform:
Dim xslTran As New XslTransform()
· используем метод Load этого объекта, чтобы загрузить в него преобразование:
xslTran.Load(Server.MapPath("PubTitles.xsl"))
· создаем объект XmlTextWriter (он будет использован для вывода результатов преобразования):
Dim writer As New XmlTextWriter _
(Server.MapPath("PubTitles_output.html"), _
System.Text.Encoding.UTF8)
· выполняем само преобразование при помощи метода Tr ansform объекта XslTransform . У этого метода - несколько вариантов. Один из вариантов его применения может выглядеть так:
xslTran.Transform(xmlDoc, Nothing, writer)
· закрываем объект Writer:
writer.Close()
Для работы с XML на Web -форме можно обойтись и совсем без объекта DataSet (и элементов управления, предназначенных для отображения данных из реляционного источника). Вместо этого можно использовать элемент управления XML Web Server Control . Он позволяет выводить на Web-странице сами документы XML или результаты их преобразований. Код XML можно передавать этому элементу управления разными способами:
· напрямую открывать их с диска (через свойство DocumentSource ). В этом случае (если вы не применили преобразования XSLT) документ XML будет выведен на форму "как есть":
XML Example
TransformSource="MyStyle.xsl" runat="server" />
· открывать их как объекты и передавать их этому элементу управления (через свойство Document ). В нашем случае XML Web Server Control называется Xml1 :
Private Sub Page_Load(ByVal sender As System.Object, _
ByVal e As System.EventArgs) Handles MyBase.Load
Dim xmlDoc As System.Xml.XmlDocument = _
New System.Xml.XmlDocument()
xmlDoc.Load(Server.MapPath("MySource.xml"))
Dim xslTran As System.Xml.Xsl.XslTransform = _
New System.Xml.Xsl.XslTransform()
xslTran.Load(Server.MapPath("MyStyle.xsl"))
Xml1.Document = xmlDoc
Xml1.Transform = xslTran
End Sub
· просто программным образом генерировать код XML и передавать этот код XML Web Server Control (через свойство DocumentContent )
· вообще напрямую вписать код XML в тег XML Web Server Control:
· выполнить преобразование и передать ему результаты преобразования
Пример, который иллюстрирует все эти возможности, представлен ниже:
Document="XmlDocument object to display"
DocumentContent="String of XML"
DocumentSource="Path to XML Document"
Transform="XslTransform object"
TransformSource="Path to XSL Transform Document"
runat =" server ">
Добавить XML Web Server Control на Web -форму можно просто перетаскиванием этого элемента управления из ToolBox или программно:
< asp : Xml id =" xmlCtl " runat =" server " />
XmlCtl . Document . Save (Server . MapPath (" xmlResult . xml "))
Работа с XML в.NET
Информатика, кибернетика и программирование
Лекция 8. Работа с XML в.NET План 1. Классы для работы с XML .NET 2. Чтение и запись потоков данных Xml 2.1. Использование класса XmlReader 2.2. Методы чтения данных 2.3. Контроль типов данных при чтении Xmlдокумента 3. Создание XMLдокумента в Visual Studio 1. Классы для работы с XML .NET Мно
Украинкский
Лекция 8. Работа с XML в.NET
План
1. Классы для работы с
2.1. Использование класса XmlReader
2.2. Методы чтения данных
Xml -документа
1. Классы для работы с XML . NET
Многие составляющие технологии.NET неразрывно связаны с XML. А значит, XML хорошо поддерживается со стороны Framework Class Library. В.NET поддерживаются следующие технологии:
- XML 1.0
- пространства имен XML
- XSD схемы
- выражения XPath
- XSL преобразования
- DOM Level 1 Core, DOM Level 2 Core
Среда. NET Framework не только позволяет применять XML в создаваемых приложениях, но и сама применяет его в конфигурационных файлах, документации по исходному коду и в манифесте сборки.
Пример 1. Манифест сборки
Классы для работы с XML собраны в пространстве имен System . Xml . Это пространство загружается вместе с классами, которые могут использоваться для обработки данных XML .
Таблица 1. Основные классы чтения и записи данных XML
|
XmlReader |
Абстрактный класс, выполняющий чтение и обеспечивающий быструю доставку некешированных данных XML . Класс представляет собой однонаправленный синтаксический анализатор |
|
XmlWriter |
Абстрактный класс, выполняющий запись данных в виде потока или файла |
|
XmlTextReader |
Расширяет возможности класса XmlReader . Обеспечивает однонаправленный потоковый доступ к данным XML |
|
XmlTextWtiter |
Расширяет возможности класса Xml . Writer XML |
Таблица 2. Некоторые классы обработки данных XML
|
XmlNode |
Абстрактный класс, представляющий один узел в XML -документе. Базовый класс для некоторых других классов |
|
XmlDocument |
Расширяет класс XmlNode . Представляет собой реализацию DOM от W 3 C . Обеспечивает древовидное представление XML -документа в памяти с возможностями навигации и редактирования |
|
XmlNavigator |
Обеспечивает навигацию по документу |
|
XMLDataDocument |
служит мостом между хранилищами данных и реляционными данными, хранящимися в DataSet |
2. Чтение и запись потоков данных Xml
Среда. NET Framework поддерживает два способа обработки XML -документов: потоковый ввод-вывод и DOM . Абстрактные классы XmlReader , XmlWriter и порожденные от них классы поддерживают потоковую модель ввода-вывода.
Классы, основанные на XmlReader обеспечивают быстрый однонаправленный курсор , который организует поток данных XML для обработки.
От XmlReader порождены следующие классы:
От XmlWriter порождены следующие классы:
|
XmlTextWriter |
Расширяет возможности класса Xml . Writer . Обеспечивает быструю однонаправленную генерацию потоков XML |
|
XmlQueryOutput |
Расширяет возможности класса Xml . Writer , О беспечива ет функциональность, необходимую для вывода результатов преобразований XSLT. |
Для работы с данными каждый из классов предоставляет необходимые методы.
2.1. Использование класса XmlReader
Пример чтения данных XML из файла. Данные хранятся в файле "book2.xml" и представляют собой описание книжного каталога:
Создадим форму с двумя кнопками и текстовым редактором (richTextBox1), в который будем размещать прочитанные данные.
При нажатии кнопки ReadXml выполняется чтение и разбор XML -файла и вывод его в текстовый редактор. Обработчик кнопки ReadXML_Click :
private void ReadXML_Click(object sender, EventArgs e)
//чтение файла
RichTextBox1.Clear(); //очистка редактора
XmlReader rdr = XmlReader .Create("book2.xml" );//создание объекта rdr
while (rdr.Read())
if (rdr.NodeType == XmlNodeType .Text)
RichTextBox1.AppendText(rdr.Value + "\r\n" );
Класс XmlReader является абстрактным, т.есть, для таких классов нельзя создавать объекты оператором new . Для того, чтобы его можно было использовать, нужно включить в него статические методы.
В этом обработчике используется статический метод Create , который возвращает объект XmlReader . Дальше в цикле while выполняется чтение каждой строки файла. По мере чтения производится проверка свойства NodeType . Если узел является текстовым, в текстовый редактор добавляется его содержимое.

2.2. Методы чтения данных
Классы для работы с XML предоставляют несколько способов передвижения по XML -документу. Например, метод Read() перемещает на следующий узел. Потом можно проверить, имеет ли этот узел содержимое (HasValue ()) или атрибуты (YasAttributes ()).
Основные методы анализа документа представлены в таблице ниже.
|
Read() |
читает очередную запись и перемещает на следующий узел |
|
HasValue () |
возвращает true false противном случае |
|
HasAttributes () |
просматривает элемент на наличие атрибутов. Возвращает true , если элемент имеет содержимое, false противном случае |
|
ReadStartElement() |
проверяет, является ли узел корневым, после чего смещается на следующий узел. Если узел не корневой, возбуждается исключение XmlException. |
|
IsStartElement() |
аналогичен методу ReadStartElement() |
|
ReadString() |
чтение одной строки из файла, содержащего документ |
|
ReadElementString() |
подобен методу ReadString () за исключением того, что ему можно передать имя элемента. Если следующий узел с содержимым не является начальным дескриптором или если параметр Name не совпадает с текущим параметром узла, возбуждается исключение |
|
MoveToContent() |
перемещение к содержимому узла |
Пример 2. Вывод отдельных элементов XML -документа
Рассмотрим применения метода ReadElementString () и других методов, а также применение файловых потоков (чтения из файла).
Не забыть подключить using System.IO;
Добавим на форму кнопку Read from file . Код обработчика будет следующим:
private void btmReadXml2_Click(object sender, EventArgs e)
//чтение только название книг (элемент "TITLE"
RichTextBox1.Clear();
FileStream fs = new FileStream ("book2.xml" , FileMode .Open);
XmlReader rdr = XmlReader .Create(fs);
while (!rdr.EOF)
//Если попадаем на тип элемента, проверить его и загрузить в окно
RichTextBox1.AppendText(rdr.ReadElementString() + "\r\n" );
else
// в противном случае - переместиться на след.запись
Rdr.Read();
В этом примере в цикле while используется метод MoveToContent() для поиска узла типа XmlNodeType . Element с названием книги rdr.Name == "TITLE" )
if (rdr.MoveToContent() == XmlNodeType .Element && rdr.Name == "TITLE" )
Просмотр выполняется до конца файла (условие цикла
while (!rdr.EOF)
Если типом узла не является элемент или его имя не совпадает с "TITLE " , то вызывается метод Read () для перехода к следующему узлу. Если очередной узел "TITLE " найден, его содержимое добавляется в окно вывода. Таким образом, будут выведены только названия книг.
2.3. Контроль типов данных при чтении Xml -документа
Класс XmlReader также позволяет считывать данные со строгим контролем типов. Для этого используются методы ReadElementContentAs ... ReadElementContentAsDouble (), ReadElementContentAsBoolean () и другие. Далее показано как можно считывать значение в десятичном формате и выполнять вычисления. В примере выбирается значение цены книги, которое увеличивается на 25%.
Создадим еще одну кнопку с надписью New Price , а в ее обработчике напишем код:
private void btnNewPrice_Click(object sender, EventArgs e)
//Обработчик кнопки NewPrice - контроль типов
RichTextBox1.Clear();
XmlReader rdr = XmlReader .Create("book2.xml" );
while (rdr.Read())
if (rdr.NodeType == XmlNodeType .Element)
if (rdr.Name == "PRICE" )
decimal price = rdr.ReadElementContentAsDecimal();
RichTextBox1.AppendText("Curent Price = " + price+ "\r\n" );
Price += price * (decimal )0.25;
RichTextBox1.AppendText("New Price = " + price + "\r\n\r\n" );
else if (rdr.Name== "TITLE" )
RichTextBox1.AppendText(rdr.ReadElementContentAsString()+ "\r\n" );
rdr.Close();
Если это значение не может быть преобразовано к требуемому типу, возбуждается исключение FormatException .
Компилируем и запускаем на выполнение наш проект.
В результате получаем сообщение об ошибке. Причина текст элемента имеет вид:
< PRICE >$10.95
Исправим все элементы < PRICE > 10.95,
а документ сохраним под именем ("book 3 .xml" );
В результате получим:

3. Создание XML -документа в Visual Studio
Для создания XML -файла в среде Visual Studio нужно в меню File выбрать New -> File . В окне создания выбрать Xml -файл


Откроется Xml -редактор, в котором можно вводить элементы Xml . Редактор автоматически проверяет ошибки и подставляет закрывающие теги. Созданный файл можно сохранить в нужном месте на диске командой SaveXmlFile . xml As ...

А также другие работы, которые могут Вас заинтересовать |
|||
| 25682. | Тонкая кишка | 57.5 KB | |
| Клетки кишечного эпителия у 4недельного эмбриона не дифференцированы и характеризуются высокой пролиферативной активностью. В это время среди эндокриноцитов преобладают переходные клетки с недифференцированными гранулами выявляются ЕСклетки Gклетки и Sклетки. В плодном периоде преобладают ЕСклетки большинство из которых не сообщается с просветом крипт закрытый тип; в более позднем плодном периоде появляется открытый тип клеток. Крипты содержат камбиальные элементы эпителия и дифференцирующиеся из них клетки. | |||
| 25683. | солевом обмене веществ. | 44.5 KB | |
| Кроме того эти ткани принимают участие в водносолевом обмене веществ. Хрящевые ткани входят в состав органов дыхательной системы суставов межпозвоночных дисков и др. В свежей хрящевой ткани содержится около 7080 воды 1015 органических веществ и 47 солей. | |||
| 25684. | Эмбриогенез | 239.5 KB | |
| Вместе с тем появляются особенности отличающие развитие человека от развития других представителей позвоночных. Процесс внутриутробного развития зародыша человека продолжается в среднем 280сут 10 лунных месяцев. Эмбриональное развитие человека принято делить на 3 периода: начальный 1я неделя зародышевый 2 8я неделя плодный с 9й недели развития до рождения ребенка. | |||
| 25685. | Эпителиальные ткани. Поверхностные эпителии | 36 KB | |
| Питание эпителиоцитов осуществляется диффузно через базальную мембрану со стороны подлежащей соединительной ткани с которой эпителий находится в тесном взаимодействии. В соответствии с формой клеток составляющих однослойный эпителий последние подразделяются на плоские сквамозные кубические и призматические столбчатые. 1Однослойный эпителий может быть однорядным и многорядным. Такой эпителий называют еще изоморфным. | |||
| 25686. | Яички | 60 KB | |
| В постнатальном периоде в семенных канальцах гоноциты размножаются а эпителий половых шнуров сохраняется в качестве поддерживающих клеток. Базальный слой внутренний волокнистый слой расположенный между двумя базальными мембранами сперматогенного эпителия и миоидных клеток состоит из сети коллагеновых волокон. Непосредственно к миоидному слою примыкает неклеточный слой образованный базальной мембраной миоидных клеток и коллагеновыми волокнами. За ними расположен слой состоящий из фибробластоподобных клеток прилежащий к базальной... | |||
| 25687. | Яичники | 58.5 KB | |
| Около половины овогоний с 3го месяца развития начинает дифференцироваться в овоцит первого порядка период малого роста находящийся в профазе мейоза. К моменту рождения число овогоний прогрессивно уменьшается и составляет около 45 большая часть клеток подвергается атрезии основные клетки представляют собой вступившие в период роста овоциты 1го порядка. 2 стадия период роста протекает в функционирующем яичнике и состоит в превращении овоцита 1го порядка первичного фолликула в овоцит 1го порядка в зрелом фолликуле. 3 стадия... | |||
| 25688. | Мужские половые клетки | 40 KB | |
| Скорость их движения у человека 3050мкм с Целенаправленному движению способствуют хемотаксис движение к химическому раздражителю или от него и реотаксис движение против тока жидкости. Мужские половые клетки человека сперматозоиды или спермии длиной 70мкм имеют головку и хвост. В ядре сперматозоида человека содержится 23 хромосомы одна из которых является половой X или У остальные аутосомами. | |||
| 25689. | Понятие о системе крови. Эритроциты | 47 KB | |
| Система крови включает в себя кровь органы кроветворения красный костный мозг тимус селезенку лимфатические узлы лимфоидную ткань некроветворных органов. Элементы системы крови имеют общее происхождение из мезенхимы и структурнофункциональные особенности подчиняются общим законам нейрогуморальной регуляции объединены тесным взаимодействием всех звеньев. Так постоянный состав периферической крови поддерживается сбалансированными процессами новообразования гемопоэза и разрушения клеток крови. | |||
| 25690. | МОЧЕВЫДЕЛИТЕЛЬНАЯ СИСТЕМА | 41 KB | |
| Длина его канальцев до 50мм а всех нефронов в среднем около 100 км. Остальные 15 нефронов располагаются в почке так что их почечные тельца извитые проксимальные и дистальные отделы лежат в корковом веществе на границе с мозговым веществом. Таким образом корковое и мозговое вещества почек образованы различными отделами трех разновидностей нефронов. Корковое вещество составляют почечные тельца извитые проксимальные и дистальные канальцы всех типов нефронов. | |||
Представляем вашему вниманию новый курс от команды The Codeby - "Тестирование Веб-Приложений на проникновение с нуля". Общая теория, подготовка рабочего окружения, пассивный фаззинг и фингерпринт, Активный фаззинг, Уязвимости, Пост-эксплуатация, Инструментальные средства, Social Engeneering и многое другое.
XML DOM 2
В предыдущей статье были описаны общие понятия касающиеся XML. В этой статье научимся выполнять основные действия, связанные с изменением, добавлением, поиском в XML файле.
XML файл, который используется для примера.
xml dom
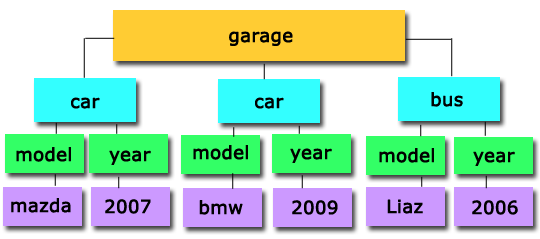
В данный момент, наш файл содержит следующую структуру:

Взаимоотношение между узлами в XML DOM , основные моменты:
1. Любой узел в DOM дереве имеет родителя ParentNode . В нашем примере garage является родителем для обоих элементов car, а оба элемента car, являются в свою очередь родителями для элементов: model и year.
Как получить родителя для xml элемента car?
Console.WriteLine(elmRoot["car"].ParentNode.Name); //Результат: garage
2. У родителя могут быть дети ChildNodes. Например, для узла garage детьми являются оба элемента car. У элементов car, тоже есть дети model и year.
ChildNodes , представляет собой коллекцию, которая хранит все дочерние xml элементы, чтобы обратиться к нужному элементу, нужно указать его индекс. (Индекс всегда начинается с нуля!)
Например: как получить первый дочерний элемент?
ElmRoot.ChildNodes;
3. Как и в обычной жизни ребенок может родиться первым FirstChild, или последним LastChild.
Если взять для примера элемент car, то
FirstChild - это model LastChild - это year
4. В свою очередь между дочерними элементами тоже существуют связи, они могут быть братьями или сестрами, если проводить параллели с реальной жизнью.
У ребенка может быть к примеру брат Previous Sibling и следующий брат Next Sibling
Console.WriteLine(elmRoot.ChildNodes.FirstChild.NextSibling.Name); //Результат: year Console.WriteLine(elmRoot.ChildNodes. LastChild.PreviousSibling.Name); //Результат: model
Если элемент не найден, то тогда возникает исключение: NullReferenceException, поэтому при работе с xml всегда используйте блоки try catch.
Console.WriteLine(elmRoot.ChildNodes. LastChild.NextSibling.Name); Console.WriteLine(elmRoot.ChildNodes. FirstChild.PreviousSibling.Name);
LastChild является NextSibling;
FirstChild является PreviousSibling;
С помощью выше описанных методов можно легко переместиться к нужному узлу и получить любое нужное вам значение.
Как получить значение xml элемента?
Значение xml элемента можно получить при помощи свойства InnerText, например:
Console.WriteLine(elmRoot["car"].FirstChild.InnerText); //Результат: mazda
Ещё один способ, чтобы получить это же значение xml элемента:
Console.WriteLine(elmRoot.FirstChild.FirstChild.InnerText); //Результат: mazda
Последовательность перемещений по DOM дереву:
Garage -> car -> model -> Мазда
Получаем год:
ElmRoot["car"].LastChild.InnerText; //Результат: 2007
Последовательность:
Garage -> car -> year -> 2007
Ещё пример: 3 способа, для получения одного и того же результата.
Console.WriteLine(elmRoot.LastChild.FirstChild.InnerText); Console.WriteLine(elmRoot["car"].NextSibling.FirstChild.InnerText); Console.WriteLine(elmRoot.ChildNodes.Item(1).FirstChild.InnerText); //Результат: BMW
Если надо получить год для элемента со значением Mazda:
Console.WriteLine(elmRoot.FirstChild.LastChild.InnerText); //Результат: 2007
Для BMW (два способа, получить один и тот же результат)
Console.WriteLine(elmRoot.ChildNodes.Item(1). ChildNodes.Item(1).InnerText); Console.WriteLine(elmRoot.ChildNodes.ChildNodes.InnerText); //Результат: 2009
Как изменить значения xml элемента?
С помощью свойства InnerText() можно, как получить, так и изменить значение xml элемента, например изменим год.
//Устанавливаем новое значение elmRoot.FirstChild.LastChild.InnerText = "2010"; //Выводим новое значение на экран консоли Console.WriteLine(elmRoot.FirstChild.ChildNodes.Item(1).InnerText); //Результат: 2010
При этом нужно помнить, что все изменения происходят с виртуальным xml файлом, если Вы откроете физический файл, то увидите, что по-прежнему в нём указан год 2007.
Для того, чтобы изменения вступили в силу, нужно воспользоваться методом Save, например:
ElmRoot.Save("имя xml файла или поток");
Теперь информация будет изменена в «физическом» xml файле.
Как получить количество дочерних элементов?
Console.WriteLine(elmRoot.FirstChild.ChildNodes.Count);garage -> car содержит 2 ребенка: model и year
Console.WriteLine(elmRoot.FirstChild.FirstChild.ChildNodes.Count);
garage -> car -> model содержит 1 дочерний xml элемент.
Обращение к дочерним элементам
по индексу
ElmRoot.ChildNodes.Name; elmRoot.ChildNodes.Name; //Результат: car
С помощью цикла
Foreach (XmlNode nod in elmRoot.ChildNodes) { Console.WriteLine(nod.Name); } //Результат: car, car
Как получить имя xml элемента?
elmRoot.Name; //Результат: garageСоздание нового XML элемента
Создадим новый элемент в нашем XML документе, чтобы он отличался от двух других (car) назовём его автобус (bus).
При создании нового элемента воспользуемся рекомендацией с сайта msdn и вместо стандартного new XmlElement воспользуемся методом CreateElement.
XmlElement elm = xmlDoc.CreateElement("bus");
Создание и добавление нового xml элемента
Создадим новый xml элемент по имени «BUS».
XmlElement elmRoot = xmlDoc.DocumentElement; Console.WriteLine(elmRoot.ChildNodes.Count); //car, car XmlElement elmNew = xmlDoc.CreateElement("bus"); elmRoot.AppendChild(elmNew); Console.WriteLine(elmRoot.ChildNodes.Count); //3 car, car, bus xmlDoc.Save("имя xml файла");Пояснение:
1. Сначала получаем root-элемент к которому будем крепить новые элементы.
2. В качестве проверки выведем текущее количество дочерних элементов у элемента garage: 2 (car и car)
3. Создаем новый элемент BUS
4. При помощи метода AppendChild добавляем новый элемент в дерево
5. Снова воспользуемся проверкой и выведем текущее количество элементов у элемента garage, теперь их стало 3: car, car, bus.
6. Чтобы изменения затронули физический файл, сохраняемся
В самом XML файле новый элемент будет выглядеть так:
Как добавить новый xml элемент?
Задача: создать новый XML элемент и добавить в него какое-нибудь текстовое содержимое, например год выпуска.
String strFilename = @"C:\lessons\Auto.xml"; XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(strFilename); XmlElement elmRoot = xmlDoc.DocumentElement; XmlElement elmNew = xmlDoc.CreateElement("bus"); XmlText new_txt = xmlDoc.CreateTextNode("2006"); elmRoot.AppendChild(elmNew); elmRoot.LastChild.AppendChild(new_txt); Console.WriteLine(elmRoot.ChildNodes.Name); //bus Console.WriteLine(elmRoot.ChildNodes.LastChild.InnerText); //2006 Console.Read();
В XML файле:
Для наглядности

А теперь создадим узел «bus», с такой же архитектурой, как и car, то есть добавим узлы: model, year и какое-нибудь текстовое содержимое.
Создание XML элемента с дочерними элементами
string strFilename = @"C:\lessons\Auto.xml"; //создаем новый xml документ в памяти XmlDocument xmlDoc = new XmlDocument(); //загружаем xml файл в память xmlDoc.Load(strFilename); //Получаем root-элемент XmlElement elmRoot = xmlDoc.DocumentElement; //Создаём 3 элемента: bus, model, year XmlElement elmBUS = xmlDoc.CreateElement("bus"); XmlElement elmModel = xmlDoc.CreateElement("model"); XmlElement elmYear = xmlDoc.CreateElement("year"); //Устанавливаем значения для элементов: model, year XmlText year_txt = xmlDoc.CreateTextNode("2006"); //XmlText mod_txt = xmlDoc.CreateTextNode("liaz"); добавим иначе //К элементу bus добавляем два дочерних элемента: model и year elmBUS.AppendChild(elmModel); elmBUS.AppendChild(elmYear); //Добавляем значения узлам model и year elmModel.InnerText = "liaz"; elmYear.AppendChild(year_txt); //Добавляем в дерево новый xml элемент bus elmRoot.AppendChild(elmBUS); //Проверяем, всё ли добавлено, как надо Console.WriteLine(elmRoot.ChildNodes.FirstChild.InnerText); Console.WriteLine(elmRoot.LastChild.LastChild.InnerText); //Если всё в порядке, то используем метод Save xmlDoc.Save("имя xml файла");Результат:
Как можно сократить, данный код? Например, следующим образом:
String PathXmlFile = @"C:\lessons\Auto.xml"; XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(PathXmlFile); XmlElement elmRoot = xmlDoc.DocumentElement; XmlElement elmBUS = xmlDoc.CreateElement("bus"); XmlElement elmModel = xmlDoc.CreateElement("model"); XmlElement elmYear = xmlDoc.CreateElement("year"); //Добавляем значения узлам model и year elmModel.InnerText = "liaz"; elmYear.InnerText = "2006"; elmBUS.AppendChild(elmModel); elmBUS.AppendChild(elmYear); elmRoot.AppendChild(elmBUS); //Если всё верно, то вызываем метод Save xmlDoc.Save("имя xml файла");
Ещё немного сократим код, для этого воспользуемся свойством InnerXml:
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.Load(PathXmlFile);
XmlElement elmXML = xmlDoc.CreateElement("bus");
string txt = "
Результат
Получить список элементов при помощи GetElementByTagName
GetElementByTagName возвращает XmlNodeList , в котором содержаться все элементы потомки, принадлежащие указному элементу, например, нам нужно получить все модели машин, которые хранятся в гараже:
XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(strFilename); XmlNodeList modelName = xmlDoc.GetElementsByTagName("model"); foreach (XmlNode node in modelName) { Console.WriteLine(node.InnerText); } //Результат: mazda, bmw, liaz
Обращение при помощи индекса:
String PathXmlFile = @"C:\lessons\Auto.xml"; XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(PathXmlFile); XmlNodeList modelName = xmlDoc.GetElementsByTagName("model"); Console.WriteLine(modelName.InnerText); //Результат: liaz
Как изменить текстовое содержимое, у только что созданного элемента «bus», при помощи метода GetElementByTagName?
String PathXmlFile = @"C:\lessons\Auto.xml"; XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(PathXmlFile); XmlNodeList modelName = xmlDoc.GetElementsByTagName("model"); Console.WriteLine(modelName.InnerText); //Получили значение: liaz
Либо можно изменить имя liaz на Ikarus
Console.WriteLine(modelName.InnerText = "Ikarus");