Как построить линейную регрессию в excel. Основные задачи регрессии в Excel: пример построения модели
Построение линейной регрессии, оценивание ее параметров и их значимости можно выполнить значительнее быстрей при использовании пакета анализа Excel (Регрессия). Рассмотрим интерпретацию полученных результатов в общем случае (k объясняющих переменных) по данным примера 3.6.
В таблице регрессионной статистики приводятся значения:
Множественный R – коэффициент множественной корреляции ;
R - квадрат – коэффициент детерминации R 2 ;
Нормированный R - квадрат – скорректированный R 2 с поправкой на число степеней свободы;
Стандартная ошибка – стандартная ошибка регрессии S ;
Наблюдения – число наблюдений n .
В таблице Дисперсионный анализ приведены:
1. Столбец df - число степеней свободы, равное
для строки Регрессия df = k ;
для строкиОстаток df = n – k – 1;
для строкиИтого df = n – 1.
2. Столбец SS – сумма квадратов отклонений, равная
для строки Регрессия ;
для строкиОстаток ;
для строкиИтого .
3. Столбец MS дисперсии, определяемые по формуле MS = SS /df :
для строки Регрессия – факторная дисперсия;
для строкиОстаток – остаточная дисперсия.
4. Столбец F – расчетное значение F -критерия, вычисляемое по формуле
F = MS (регрессия)/MS (остаток).
5. Столбец Значимость F –значение уровня значимости, соответствующее вычисленной F -статистике.
Значимость F = FРАСП(F- статистика, df (регрессия), df (остаток)).
Если значимость F < стандартного уровня значимости, то R 2 статистически значим.
| Коэффи-циенты | Стандартная ошибка | t-cта-тистика | P-значение | Нижние 95% | Верхние 95% | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
В этой таблице указаны:
1. Коэффициенты – значения коэффициентов a , b .
2. Стандартная ошибка –стандартные ошибки коэффициентов регрессии S a , S b .
3. t- статистика – расчетные значения t -критерия, вычисляемые по формуле:
t-статистика = Коэффициенты / Стандартная ошибка.
4.Р -значение (значимость t ) – это значение уровня значимости, соответствующее вычисленной t- статистике.
Р -значение = СТЬЮДРАСП (t -статистика, df (остаток)).
Если Р -значение < стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. Нижние 95% и Верхние 95% – нижние и верхние границы 95 %-ных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное y | Остатки e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
В таблице ВЫВОД ОСТАТКА указаны:
в столбце Наблюдение – номер наблюдения;
в столбце Предсказанное y – расчетные значения зависимой переменной;
в столбце Остатки e – разница между наблюдаемыми и расчетными значениями зависимой переменной.
Пример 3.6. Имеются данные (усл. ед.) о расходах на питание y и душевого дохода x для девяти групп семей:
| x | |||||||||
| y |
Используя результаты работы пакета анализа Excel (Регрессия), проанализируем зависимость расходов на питание от величины душевого дохода.
Результаты регрессионного анализа принято записывать в виде:
![]()
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Коэффициенты регрессии а = 65,92 и b = 0,107. Направление связи между y и x определяет знак коэффициентарегрессии b = 0,107, т.е. связь является прямой и положительной. Коэффициент b = 0,107 показывает, что при увеличении душевого дохода на 1 усл. ед. расходы на питание увеличиваются на 0,107 усл. ед.
Оценим значимость коэффициентов полученной модели. Значимость коэффициентов (a, b ) проверяется по t -тесту:
Р-значение (a ) = 0,00080 < 0,01 < 0,05
Р-значение (b ) = 0,00016 < 0,01 < 0,05,
следовательно, коэффициенты (a, b ) значимы при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости. Таким образом, коэффициенты регрессии значимы и модель адекватна исходным данным.
Результаты оценивания регрессии совместимы не только с полученными значениями коэффициентов регрессии, но и с некоторым их множеством (доверительным интервалом). С вероятностью 95 % доверительные интервалы для коэффициентов есть (38,16 – 93,68) для a и (0,0728 – 0,142) для b.
Качество модели оценивается коэффициентом детерминации R 2 .
Величина R 2 = 0,884 означает, что фактором душевого дохода можно объяснить 88,4 % вариации (разброса) расходов на питание.
Значимость R 2 проверяется по F- тесту: значимость F = 0,00016 < 0,01 < 0,05, следовательно, R 2 значим при 1 %-ном уровне, а тем более при 5 %-ном уровне значимости.
В случае парной линейной регрессии коэффициент корреляции можно определить как ![]() . Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
. Полученное значение коэффициента корреляции свидетельствует, что связь между расходами на питание и душевым доходом очень тесная.
28 Окт
Добрый день, уважаемые читатели блога! Сегодня мы поговорим о нелинейных регрессиях. Решение линейных регрессий можно посмотреть по ССЫЛКЕ .
Данный способ применяется, в основном, в экономическом моделировании и прогнозировании. Его цель – пронаблюдать и выявить зависимости между двумя показателями.
Основными типами нелинейных регрессий являются:
- полиномиальные (квадратичная, кубическая);
- гиперболическая;
- степенная;
- показательная;
- логарифмическая.
Также могут применяться различные комбинации. Например, для аналитики временных рядов в банковской сфере, страховании, демографических исследованиях используют кривую Гомпцера, которая является разновидностью логарифмической регрессии.
В прогнозировании с помощью нелинейных регрессий главное выяснить коэффициент корреляции, который покажет нам есть ли тесная взаимосвязь меду двумя параметрами или нет. Как правило, если коэффициент корреляции близок к 1, значит связь есть, и прогноз будет довольно точен. Ещё одним важным элементом нелинейных регрессий является средняя относительная ошибка (А ), если она находится в промежутке <8…10%, значит модель достаточно точна.
На этом, пожалуй, теоретический блок мы закончим и перейдём к практическим вычислениям.
У нас имеется таблица продаж автомобилей за промежуток 15 лет (обозначим его X), количество шагов измерений будет аргумент n, также имеется выручка за эти периоды (обозначим её Y), нам нужно спрогнозировать какова будет выручка в дальнейшем. Построим следующую таблицу:
Для исследования нам потребуется решить уравнение (зависимости Y от X): y=ax 2 +bx+c+e. Это парная квадратичная регрессия. Применим в этом случае метод наименьших квадратов, для выяснения неизвестных аргументов — a, b, c. Он приведёт к системе алгебраических уравнений вида:

Для решения этой системы воспользуемся, к примеру, методом Крамера. Видим, что входящие в систему суммы являются коэффициентами при неизвестных. Для их вычисления добавим в таблицу несколько столбцов (D,E,F,G,H) и подпишем соответственно смыслу вычислений — в столбце D возведём x в квадрат, в E в куб, в F в 4 степень, в G перемножим показатели x и y, в H возведём x в квадрат и перемножим с y.

Получится заполненная нужными для решения уравнения таблица вида.


Сформируем матрицу A системы, состоящую из коэффициентов при неизвестных в левых частях уравнений. Поместим её в ячейку А22 и назовём «А= «. Следуем той системе уравнений, которую мы избрали для решения регрессии.

То есть, в ячейку B21 мы должны поместить сумму столбца, где возводили показатель X в четвёртую степень — F17. Просто сошлёмся на ячейку — «=F17». Далее нам необходима сумма столбца где возводили X в куб — E17, далее идём строго по системе. Таким образом, нам необходимо будет заполнить всю матрицу.
В соответствии с алгоритмом Крамера наберём матрицу А1, подобную А, в которой вместо элементов первого столбца должны размещаться элементы правых частей уравнений системы. То есть сумма столбца X в квадрате умноженная на Y, сумма столбца XY и сумма столбца Y.

Также нам понадобятся ещё две матрицы — назовём их А2 и А3 в которых второй и третий столбцы будут состоять из коэффициентов правых частей уравнений. Картина будет такова.

Следуя избранному алгоритму, нам нужно будет вычислить значения определителей (детерминантов, D) полученных матриц. Воспользуемся формулой МОПРЕД. Результаты разместим в ячейках J21:K24.

Расчёт коэффициентов уравнения по Крамеру будем производить в ячейках напротив соответствующих детерминантов по формуле: a (в ячейке M22) — «=K22/K21»; b (в ячейке M23) — «=K23/K21»; с (в ячейке M24) — «=K24/K21».
Получим наше искомое уравнение парной квадратичной регрессии:
y=-0,074x 2 +2,151x+6,523
Оценим тесноту линейной связи индексом корреляции.

Для вычисления добавим в таблицу дополнительный столбец J (назовём его y*). Расчёта будет следующей (согласно полученному нами уравнению регрессии) — «=$m$22*B2*B2+$M$23*B2+$M$24». Поместим её в ячейку J2. Останется протянуть вниз маркер автозаполнения до ячейки J16.

Для вычисления сумм (Y-Y усредненное) 2 добавим в таблицу столбцы K и L с соответствующими формулами. Среднее по столбцу Y посчитаем с помощью функции СРЗНАЧ.

В ячейке K25 разместим формулу подсчёта индекса корреляции — «=КОРЕНЬ(1-(K17/L17))».

Видим, что значение 0,959 очень близко к 1, значит между продажами и годами есть тесная нелинейная связь.
Осталось оценить качество подгонки полученного квадратичного уравнения регрессии (индекс детерминации). Он рассчитывается по формуле квадрата индекса корреляции. То есть формула в ячейке K26 будет очень проста — «=K25*K25».

Коэффициент 0,920 близок к 1, что свидетельствует о высоком качестве подгонки.
Последним действием будет вычисление относительной ошибки. Добавим столбец и внесём туда формулу: «=ABS((C2-J2)/C2), ABS — модуль, абсолютное значение. Протянем маркером вниз и в ячейке M18 выведем среднее значение (СРЗНАЧ), назначим ячейкам процентный формат. Полученный результат — 7,79% находится в пределах допустимых значений ошибки <8…10%. Значит вычисления достаточно точны.
Если возникнет необходимость, по полученным значениям мы можем построить график.
Файл с примером прилагается — ССЫЛКА !
Категории: / / от 28.10.2017Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».
- Переходим в раздел «Параметры».
- Открывается окно параметров Excel. Переходим в подраздел «Надстройки».
- В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».
- Открывается окно доступных надстроек Эксель. Ставим галочку около пункта «Пакет анализа». Жмем на кнопку «OK».

Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк. В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.


Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае - это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ - ожидаемое значение у при заданном значении х,
x - независимая переменная,
a - отрезок на оси y для прямой линии,
b - наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у - это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ - это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.
Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.
Чтобы продемонстрировать работу надстройки, воспользуемся данными с предыдущей статьи, где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.
Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:
Щелкните ОК. На рисунке ниже показаны полученные результаты:
Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в предыдущей статье.
Регрессионный анализ - это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1×1 +…+аkxk, где хi - влияющие переменные, ai - коэффициенты регрессии, a k - число факторов.
Для данной задачи Y - это показатель уволившихся сотрудников, а влияющий фактор - зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.

На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;
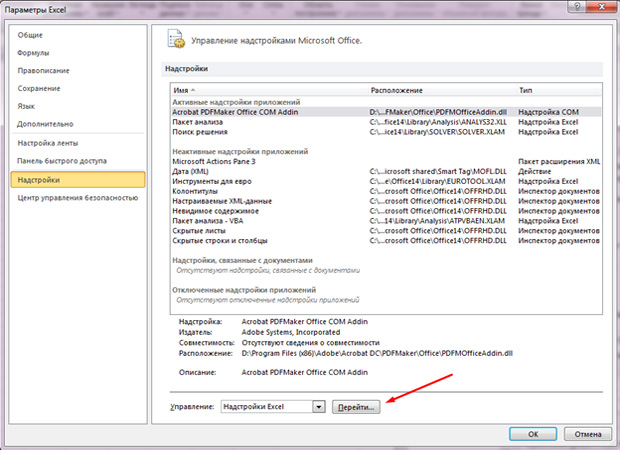
- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».

Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.

Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.

Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.
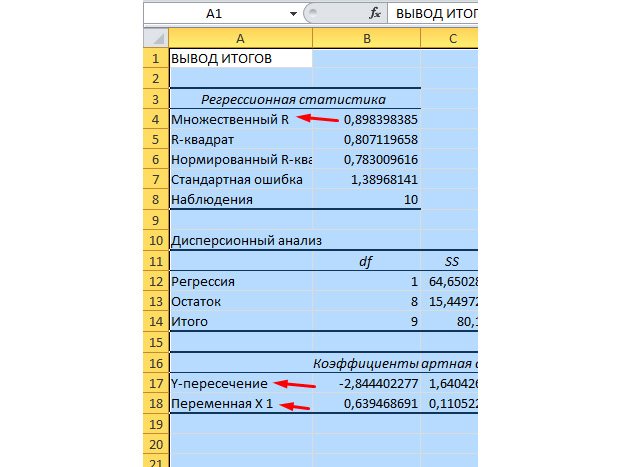
Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.

Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.

Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.