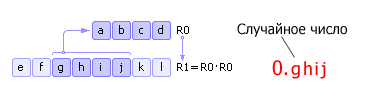Случайная последовательность чисел. Генератор псевдослучайных чисел
- Tutorial
Вы когда-нибудь задумывались, как работает Math.random()? Что такое случайное число и как оно получается? А представьте вопрос на собеседовании - напишите свой генератор случайных чисел в пару строк кода. И так, что же это такое, случайность и возможно ли ее предсказать?
Меня очень увлекают различные IT головоломки и задачки и генератор случайных чисел - одна из таких задачек. Обычно в своем телеграм канале я разбираю всякие головоломки и разные задачи с собеседований. Задача про генератор случайных чисел набрала большую популярность и мне захотелось увековечить ее в недрах одного из авторитетных источников информации - то бишь здесь, на Хабре.
Данный материал будет полезен всем тем фронтендерам и Node.js разработчикам, кто на острие технологий и хочет попасть в блокчейн проект/стартап, где вопросы про безопасность и криптографию, хотя бы на базовом уровне, спрашивают даже у фронтендеров.
Генератор псевдослучайных чисел и генератор случайных чисел
Для того, чтобы получить что-то случайное, нам нужен источник энтропии, источник некого хаоса из который мы будем использовать для генерации случайности.Этот источник используется для накопления энтропии с последующим получением из неё начального значения (initial value, seed), которое необходимо генераторам случайных чисел (ГСЧ) для формирования случайных чисел.
Генератор ПсевдоСлучайных Чисел использует единственное начальное значение, откуда и следует его псевдослучайность, в то время как Генератор Случайных Чисел всегда формирует случайное число, имея в начале высококачественную случайную величину, которая берется из различных источников энтропии.
Энтропия - это мера беспорядка. Информационная энтропия - мера неопределённости или непредсказуемости информации.Выходит, что чтобы создать псевдослучайную последовательность нам нужен алгоритм, который будет генерить некоторую последовательность на основании определенной формулы. Но такую последовательность можно будет предсказать. Тем не менее, давайте пофантазируем, как бы могли написать свой генератор случайных чисел, если бы у нас не было Math.random()
ГПСЧ имеет некоторый алгоритм, который можно воспроизвести.
ГСЧ - это получение чисел полностью из какого либо шума, возможность просчитать который стремится к нулю. При этом в ГСЧ есть определенные алгоритмы для выравнивания распределения.
Придумываем свой алгоритм ГПСЧ
Генератор псевдослучайных чисел (ГПСЧ, англ. pseudorandom number generator, PRNG) - алгоритм, порождающий последовательность чисел, элементы которой почти независимы друг от друга и подчиняются заданному распределению (обычно равномерному).Мы можем взять последовательность каких-то чисел и брать от них модуль числа. Самый простой пример, который приходит в голову. Нам нужно подумать, какую последовательность взять и модуль от чего. Если просто в лоб от 0 до N и модуль 2, то получится генератор 1 и 0:
Function* rand() {
const n = 100;
const mod = 2;
let i = 0;
while (true) {
yield i % mod;
if (i++ > n) i = 0;
}
}
let i = 0;
for (let x of rand()) {
if (i++ > 100) break;
console.log(x);
}
Эта функция генерит нам последовательность 01010101010101… и назвать ее даже псевдослучайной никак нельзя. Чтобы генератор был случайным, он должен проходить тест на следующий бит. Но у нас не стоит такой задачи. Тем не менее даже без всяких тестов мы можем предсказать следующую последовательность, значит такой алгоритм в лоб не подходит, но мы в нужном направлении.
А что если взять какую-то известную, но нелинейную последовательность, например число PI. А в качестве значения для модуля будем брать не 2, а что-то другое. Можно даже подумать на тему меняющегося значения модуля. Последовательность цифр в числе Pi считается случайной. Генератор может работать, используя числа Пи, начиная с какой-то неизвестной точки. Пример такого алгоритма, с последовательностью на базе PI и с изменяемым модулем:
Const vector = [...Math.PI.toFixed(48).replace(".","")];
function* rand() {
for (let i=3; i<1000; i++) {
if (i > 99) i = 2;
for (let n=0; n
Мы получили генератор чисел от 0 до 9, но распределение очень неравномерное и каждый раз он будет генерировать одну и ту же последовательность.
Мы можем взять не число Pi, а время в числовом представлении и это число рассматривать как последовательность цифр, причем для того, чтобы каждый раз последовательность не повторялась, мы будем считывать ее с конца. Итого наш алгоритм нашего ГПСЧ будет выглядеть так:
Function* rand() {
let newNumVector = () => [...(+new Date)+""].reverse();
let vector = newNumVector();
let i=2;
while (true) {
if (i++ > 99) i = 2;
let n=-1;
while (++n < vector.length) yield (vector[n] % i);
vector = newNumVector();
}
}
// TEST:
let i = 0;
for (let x of rand()) {
if (i++ > 100) break;
console.log(x)
}
Вот это уже похоже на генератор псевдослучайных чисел. И тот же Math.random() - это ГПСЧ, про него мы поговорим чуть позже. При этом у нас каждый раз первое число получается разным.
Собственно на этих простых примерах можно понять как работают более сложные генераторы случайных числе. И есть даже готовые алгоритмы. Для примера разберем один из них - это Линейный конгруэнтный ГПСЧ(LCPRNG).
Линейный конгруэнтный ГПСЧ
Линейный конгруэнтный ГПСЧ(LCPRNG) - это распространённый метод для генерации псевдослучайных чисел. Он не обладает криптографической стойкостью. Этот метод заключается в вычислении членов линейной рекуррентной последовательности по модулю некоторого натурального числа m, задаваемой формулой. Получаемая последовательность зависит от выбора стартового числа - т.е. seed. При разных значениях seed получаются различные последовательности случайных чисел. Пример реализации такого алгоритма на JavaScript:Const a = 45;
const c = 21;
const m = 67;
var seed = 2;
const rand = () => seed = (a * seed + c) % m;
for(let i=0; i<30; i++)
console.log(rand())
Многие языки программирования используют LСPRNG (но не именно такой алгоритм(!)).
Как говорилось выше, такую последовательность можно предсказать. Так зачем нам ГПСЧ? Если говорить про безопасность, то ГПСЧ - это проблема. Если говорить про другие задачи, то эти свойства - могут сыграть в плюс. Например для различных спец эффектов и анимаций графики может понадобиться частый вызов random. И вот тут важны распределение значений и перформанс! Секурные алгоритмы не могут похвастать скоростью работы.
Еще одно свойство - воспроизводимость. Некоторые реализации позволяют задать seed, и это очень полезно, если последовательность должна повторяться. Воспроизведение нужно в тестах, например. И еще много других вещей существует, для которых не нужен безопасный ГСЧ.
Как устроен Math.random()
Метод Math.random() возвращает псевдослучайное число с плавающей запятой из диапазона = crypto.getRandomValues(new Uint8Array(1)); console.log(rvalue)
Но, в отличие от ГПСЧ Math.random(), этот метод очень ресурсоемкий. Дело в том, что данный генератор использует системные вызовы в ОС, чтобы получить доступ к источникам энтропии (мак адрес, цпу, температуре, etc…).Первой широко используемой технологией создания случайного числа был алгоритм, предложенный Лехмером, который известен как метод линейного конгруента. Этот алгоритм параметризуется четырьмя числами следующим образом:
Последовательность случайных чисел {X n } получается с помощью следующего итерационного равенства:
X n +1 = (a X n + c) mod m
Если m, а и с являются целыми, то создается последовательность целых чисел в диапазоне 0 X n < m.
Выбор значений для а, с и m является критичным для разработки хорошего генератора случайных чисел.
Очевидно, что m должно быть очень большим, чтобы была возможность создать много случайных чисел. Считается, что m должно быть приблизительно равно максимальному положительному целому числу для данного компьютера. Таким образом, обычно m близко или равно 2 31 .
Существует три критерия, используемые при выборе генератора случайных чисел:
1. Функция должна создавать полный период, т.е. все числа между 0 и m до того, как создаваемые числа начнут повторяться.
2. Создаваемая последовательность должна появляться случайно. Последовательность не является случайной, так как она создается детерминированно, но различные статистические тесты, которые могут применяться, должны показывать, что последовательность случайна.
3. Функция должна эффективно реализовываться на 32-битных процессорах.
Значения а, с и m должны быть выбраны таким образом, чтобы эти три критерия выполнялись. В соответствии с первым критерием можно показать, что если m является простым и с = 0, то при определенном значении а период, создаваемый функцией, будет равен m-1. Для 32-битной арифметики соответствующее простое значение m = 2 31 - 1. Таким образом, функция создания псевдослучайных чисел имеет вид:
X n +1 = (a X n) mod (2 31 - 1)
Только небольшое число значений а удовлетворяет всем трем критериям. Одно из таких значений есть а = 7 5 = 16807, которое использовалось в семействе компьютеров IBM 360. Этот генератор широко применяется и прошел более тысячи тестов, больше, чем все другие генераторы псевдослучайных чисел.
Сила алгоритма линейного конгруента в том, что если сомножитель и модуль (основание) соответствующим образом подобраны, то результирующая последовательность чисел будет статистически неотличима от последовательности, являющейся случайной из набора 1, 2, ..., m-1. Но не может быть случайности в последовательности, полученной с использованием алгоритма, независимо от выбора начального значения Х 0 . Если значение выбрано, то оставшиеся числа в последовательности будут предопределены. Это всегда учитывается при криптоанализе.
Если противник знает, что используется алгоритм линейного конгруента, и если известны его параметры (а = 7 5 , с = 0, m = 2 31 - 1), то, если раскрыто одно число, вся последовательность чисел становится известна. Даже если противник знает только, что используется алгоритм линейного конгруента, знания небольшой части последовательности достаточно для определения параметров алгоритма и всех последующих чисел. Предположим, что противник может определить значения Х 0 , Х 1 , Х 2 , Х 3 . Тогда:
Х 1 = (а Х 0 + с) mod mХ 2 = (а Х 1 + с) mod mХ 3 = (а Х 2 + с) mod m
Эти равенства позволяют найти а, с и m.
Таким образом, хотя алгоритм и является хорошим генератором псевдослучайной последовательности чисел, желательно, чтобы реально используемая последовательность была непредсказуемой, поскольку в этом случае знание части последовательности не позволит определить будущие ее элементы. Эта цель может быть достигнута несколькими способами. Например, использование внутренних системных часов для модификации потока случайных чисел. Один из способов применения часов состоит в перезапуске последовательности после N чисел, используя текущее значение часов по модулю m в качестве нового начального значения. Другой способ состоит в простом добавлении значения текущего времени к каждому случайному числу по модулю m.
Заметим, что в идеале кривая плотности распределения случайных чисел выглядела бы так, как показано на рис. 22.3 . То есть в идеальном случае в каждый интервал попадает одинаковое число точек: N i = N /k , где N общее число точек, k количество интервалов, i = 1, , k .
Рис. 22.3. Частотная диаграмма выпадения случайных чисел,
порождаемых идеальным генератором теоретическиСледует помнить, что генерация произвольного случайного числа состоит из двух этапов:
- генерация нормализованного случайного числа (то есть равномерно распределенного от 0 до 1);
- преобразование нормализованных случайных чисел r i в случайные числа x i , которые распределены по необходимому пользователю (произвольному) закону распределения или в необходимом интервале.
Генераторы случайных чисел по способу получения чисел делятся на:
- физические;
- табличные;
- алгоритмические.
Физические ГСЧ
Примером физических ГСЧ могут служить: монета («орел» 1, «решка» 0); игральные кости; поделенный на секторы с цифрами барабан со стрелкой; аппаратурный генератор шума (ГШ), в качестве которого используют шумящее тепловое устройство, например, транзистор (рис. 22.422.5 ).
Рис. 22.4. Схема аппаратного метода генерации случайных чисел Рис. 22.5. Диаграмма получения случайных чисел аппаратным методом
Задача «Генерация случайных чисел при помощи монеты»
Сгенерируйте случайное трехразрядное число, распределенное по равномерному закону в интервале от 0 до 1, с помощью монеты. Точность три знака после запятой.
Первый способ решения задачи
Подбросьте монету 9 раз, и если монета упала решкой, то запишите «0», если орлом, то «1». Итак, допустим, что в результате эксперимента получили случайную последовательность 100110100.Начертите интервал от 0 до 1. Считывая числа в последовательности слева направо, разбивайте интервал пополам и выбирайте каждый раз одну из частей очередного интервала (если выпал 0, то левую, если выпала 1, то правую). Таким образом, можно добраться до любой точки интервала, сколь угодно точно.
Итак, 1 : интервал делится пополам и , выбирается правая половина, интервал сужается: . Следующее число, 0 : интервал делится пополам и , выбирается левая половина , интервал сужается: . Следующее число, 0 : интервал делится пополам и , выбирается левая половина , интервал сужается: . Следующее число, 1 : интервал делится пополам и , выбирается правая половина , интервал сужается: .
По условию точности задачи решение найдено: им является любое число из интервала , например, 0.625.
В принципе, если подходить строго, то деление интервалов нужно продолжить до тех пор, пока левая и правая границы найденного интервала не СОВПАДУТ между собой с точностью до третьего знака после запятой. То есть с позиций точности сгенерированное число уже не будет отличимо от любого числа из интервала, в котором оно находится.
Второй способ решения задачи
Разобьем полученную двоичную последовательность 100110100 на триады: 100, 110, 100. После перевода этих двоичных чисел в десятичные получаем: 4, 6, 4. Подставив спереди «0.», получим: 0.464. Таким методом могут получаться только числа от 0.000 до 0.777 (так как максимум, что можно «выжать» из трех двоичных разрядов это 111 2 = 7 8) то есть, по сути, эти числа представлены в восьмеричной системе счисления. Для перевода восьмеричного числа в десятичное представление выполним:
0.464 8 = 4 · 8 1 + 6 · 8 2 + 4 · 8 3 = 0.6015625 10 = 0.602 10 .
Итак, искомое число равно: 0.602.Табличные ГСЧ
Табличные ГСЧ в качестве источника случайных чисел используют специальным образом составленные таблицы, содержащие проверенные некоррелированные, то есть никак не зависящие друг от друга, цифры. В табл. 22.1 приведен небольшой фрагмент такой таблицы. Обходя таблицу слева направо сверху вниз, можно получать равномерно распределенные от 0 до 1 случайные числа с нужным числом знаков после запятой (в нашем примере мы используем для каждого числа по три знака). Так как цифры в таблице не зависят друг от друга, то таблицу можно обходить разными способами, например, сверху вниз, или справа налево, или, скажем, можно выбирать цифры, находящиеся на четных позициях.
Таблица 22.1.
Случайные цифры. Равномерно
распределенные от 0 до 1 случайные числа
Случайные цифры Равномерно распределенные
от 0 до 1 случайные числа9 2 9 2 0 4 2 6 0.929 9 5 7 3 4 9 0 3 0.204 5 9 1 6 6 5 7 6 0.269 Достоинство данного метода в том, что он дает действительно случайные числа, так как таблица содержит проверенные некоррелированные цифры. Недостатки метода: для хранения большого количества цифр требуется много памяти; большие трудности порождения и проверки такого рода таблиц, повторы при использовании таблицы уже не гарантируют случайности числовой последовательности, а значит, и надежности результата.
Находится таблица, содержащая 500 абсолютно случайных проверенных чисел (взято из книги И. Г. Венецкого, В. И. Венецкой «Основные математико-статистические понятия и формулы в экономическом анализе»).
Алгоритмические ГСЧ
Числа, генерируемые с помощью этих ГСЧ, всегда являются псевдослучайными (или квазислучайными), то есть каждое последующее сгенерированное число зависит от предыдущего:
r i + 1 = f (r i ) .
Последовательности, составленные из таких чисел, образуют петли, то есть обязательно существует цикл, повторяющийся бесконечное число раз. Повторяющиеся циклы называются периодами .
Достоинством данных ГСЧ является быстродействие; генераторы практически не требуют ресурсов памяти, компактны. Недостатки: числа нельзя в полной мере назвать случайными, поскольку между ними имеется зависимость, а также наличие периодов в последовательности квазислучайных чисел.
Рассмотрим несколько алгоритмических методов получения ГСЧ:
- метод серединных квадратов;
- метод серединных произведений;
- метод перемешивания;
- линейный конгруэнтный метод.
Метод серединных квадратов
Имеется некоторое четырехзначное число R 0 . Это число возводится в квадрат и заносится в R 1 . Далее из R 1 берется середина (четыре средних цифры) новое случайное число и записывается в R 0 . Затем процедура повторяется (см. рис. 22.6 ). Отметим, что на самом деле в качестве случайного числа необходимо брать не ghij , а 0.ghij с приписанным слева нулем и десятичной точкой. Этот факт отражен как на рис. 22.6 , так и на последующих подобных рисунках.
Рис. 22.6. Схема метода серединных квадратов Недостатки метода: 1) если на некоторой итерации число R 0 станет равным нулю, то генератор вырождается, поэтому важен правильный выбор начального значения R 0 ; 2) генератор будет повторять последовательность через M n шагов (в лучшем случае), где n разрядность числа R 0 , M основание системы счисления.
Для примера на рис. 22.6 : если число R 0 будет представлено в двоичной системе счисления, то последовательность псевдослучайных чисел повторится через 2 4 = 16 шагов. Заметим, что повторение последовательности может произойти и раньше, если начальное число будет выбрано неудачно.
Описанный выше способ был предложен Джоном фон Нейманом и относится к 1946 году. Поскольку этот способ оказался ненадежным, от него очень быстро отказались.
Метод серединных произведений
Число R 0 умножается на R 1 , из полученного результата R 2 извлекается середина R 2 * (это очередное случайное число) и умножается на R 1 . По этой схеме вычисляются все последующие случайные числа (см. рис. 22.7 ).
Рис. 22.7. Схема метода серединных произведений Метод перемешивания
В методе перемешивания используются операции циклического сдвига содержимого ячейки влево и вправо. Идея метода состоит в следующем. Пусть в ячейке хранится начальное число R 0 . Циклически сдвигая содержимое ячейки влево на 1/4 длины ячейки, получаем новое число R 0 * . Точно так же, циклически сдвигая содержимое ячейки R 0 вправо на 1/4 длины ячейки, получаем второе число R 0 ** . Сумма чисел R 0 * и R 0 ** дает новое случайное число R 1 . Далее R 1 заносится в R 0 , и вся последовательность операций повторяется (см. рис. 22.8 ).
Рис. 22.8. Схема метода перемешивания Обратите внимание, что число, полученное в результате суммирования R 0 * и R 0 ** , может не уместиться полностью в ячейке R 1 . В этом случае от полученного числа должны быть отброшены лишние разряды. Поясним это для рис. 22.8 , где все ячейки представлены восемью двоичными разрядами. Пусть R 0 * = 10010001 2 = 145 10 , R 0 ** = 10100001 2 = 161 10 , тогда R 0 * + R 0 ** = 100110010 2 = 306 10 . Как видим, число 306 занимает 9 разрядов (в двоичной системе счисления), а ячейка R 1 (как и R 0 ) может вместить в себя максимум 8 разрядов. Поэтому перед занесением значения в R 1 необходимо убрать один «лишний», крайний левый бит из числа 306, в результате чего в R 1 пойдет уже не 306, а 00110010 2 = 50 10 . Также заметим, что в таких языках, как Паскаль, «урезание» лишних битов при переполнении ячейки производится автоматически в соответствии с заданным типом переменной.
Линейный конгруэнтный метод
Линейный конгруэнтный метод является одной из простейших и наиболее употребительных в настоящее время процедур, имитирующих случайные числа. В этом методе используется операция mod(x , y ) , возвращающая остаток от деления первого аргумента на второй. Каждое последующее случайное число рассчитывается на основе предыдущего случайного числа по следующей формуле:
r i + 1 = mod(k · r i + b , M ) .
Последовательность случайных чисел, полученных с помощью данной формулы, называется линейной конгруэнтной последовательностью . Многие авторы называют линейную конгруэнтную последовательность при b = 0 мультипликативным конгруэнтным методом , а при b ≠ 0 смешанным конгруэнтным методом .
Для качественного генератора требуется подобрать подходящие коэффициенты. Необходимо, чтобы число M было довольно большим, так как период не может иметь больше M элементов. С другой стороны, деление, использующееся в этом методе, является довольно медленной операцией, поэтому для двоичной вычислительной машины логичным будет выбор M = 2 N , поскольку в этом случае нахождение остатка от деления сводится внутри ЭВМ к двоичной логической операции «AND». Также широко распространен выбор наибольшего простого числа M , меньшего, чем 2 N : в специальной литературе доказывается, что в этом случае младшие разряды получаемого случайного числа r i + 1 ведут себя так же случайно, как и старшие, что положительно сказывается на всей последовательности случайных чисел в целом. В качестве примера можно привести одно из чисел Мерсенна , равное 2 31 1 , и таким образом, M = 2 31 1 .
Одним из требований к линейным конгруэнтным последовательностям является как можно большая длина периода. Длина периода зависит от значений M , k и b . Теорема, которую мы приведем ниже, позволяет определить, возможно ли достижение периода максимальной длины для конкретных значений M , k и b .
Теорема . Линейная конгруэнтная последовательность, определенная числами M , k , b и r 0 , имеет период длиной M тогда и только тогда, когда:
- числа b и M взаимно простые;
- k 1 кратно p для каждого простого p , являющегося делителем M ;
- k 1 кратно 4, если M кратно 4.
Наконец, в заключение рассмотрим пару примеров использования линейного конгруэнтного метода для генерации случайных чисел.
Было установлено, что ряд псевдослучайных чисел, генерируемых на основе данных из примера 1, будет повторяться через каждые M /4 чисел. Число q задается произвольно перед началом вычислений, однако при этом следует иметь в виду, что ряд производит впечатление случайного при больших k (а значит, и q ). Результат можно несколько улучшить, если b нечетно и k = 1 + 4 · q в этом случае ряд будет повторяться через каждые M чисел. После долгих поисков k исследователи остановились на значениях 69069 и 71365 .
Генератор случайных чисел, использующий данные из примера 2, будет выдавать случайные неповторяющиеся числа с периодом, равным 7 миллионам.
Мультипликативный метод генерации псевдослучайных чисел был предложен Д. Г. Лехмером (D. H. Lehmer) в 1949 году.
Проверка качества работы генератора
От качества работы ГСЧ зависит качество работы всей системы и точность результатов. Поэтому случайная последовательность, порождаемая ГСЧ, должна удовлетворять целому ряду критериев.
Осуществляемые проверки бывают двух типов:
- проверки на равномерность распределения;
- проверки на статистическую независимость.
Проверки на равномерность распределения
1) ГСЧ должен выдавать близкие к следующим значения статистических параметров, характерных для равномерного случайного закона:
2) Частотный тест
Частотный тест позволяет выяснить, сколько чисел попало в интервал (m r σ r ; m r + σ r ) , то есть (0.5 0.2887; 0.5 + 0.2887) или, в конечном итоге, (0.2113; 0.7887) . Так как 0.7887 0.2113 = 0.5774 , заключаем, что в хорошем ГСЧ в этот интервал должно попадать около 57.7% из всех выпавших случайных чисел (см. рис. 22.9 ).
Рис. 22.9. Частотная диаграмма идеального ГСЧ
в случае проверки его на частотный тестТакже необходимо учитывать, что количество чисел, попавших в интервал (0; 0.5) , должно быть примерно равно количеству чисел, попавших в интервал (0.5; 1) .
3) Проверка по критерию «хи-квадрат»
Критерий «хи-квадрат» (χ 2 -критерий) это один из самых известных статистических критериев; он является основным методом, используемым в сочетании с другими критериями. Критерий «хи-квадрат» был предложен в 1900 году Карлом Пирсоном. Его замечательная работа рассматривается как фундамент современной математической статистики.
Для нашего случая проверка по критерию «хи-квадрат» позволит узнать, насколько созданный нами реальный ГСЧ близок к эталону ГСЧ , то есть удовлетворяет ли он требованию равномерного распределения или нет.
Частотная диаграмма эталонного ГСЧ представлена на рис. 22.10 . Так как закон распределения эталонного ГСЧ равномерный, то (теоретическая) вероятность p i попадания чисел в i -ый интервал (всего этих интервалов k ) равна p i = 1/k . И, таким образом, в каждый из k интервалов попадет ровно по p i · N чисел (N общее количество сгенерированных чисел).
Рис. 22.10. Частотная диаграмма эталонного ГСЧ Реальный ГСЧ будет выдавать числа, распределенные (причем, не обязательно равномерно!) по k интервалам и в каждый интервал попадет по n i чисел (в сумме n 1 + n 2 + + n k = N ). Как же нам определить, насколько испытываемый ГСЧ хорош и близок к эталонному? Вполне логично рассмотреть квадраты разностей между полученным количеством чисел n i и «эталонным» p i · N . Сложим их, и в результате получим:
χ 2 эксп. = (n 1 p 1 · N ) 2 + (n 2 p 2 · N ) 2 + + (n k p k · N ) 2 .
Из этой формулы следует, что чем меньше разность в каждом из слагаемых (а значит, и чем меньше значение χ 2 эксп. ), тем сильнее закон распределения случайных чисел, генерируемых реальным ГСЧ, тяготеет к равномерному.
В предыдущем выражении каждому из слагаемых приписывается одинаковый вес (равный 1), что на самом деле может не соответствовать действительности; поэтому для статистики «хи-квадрат» необходимо провести нормировку каждого i -го слагаемого, поделив его на p i · N :
Наконец, запишем полученное выражение более компактно и упростим его:
Мы получили значение критерия «хи-квадрат» для экспериментальных данных.
В табл. 22.2 приведены теоретические значения «хи-квадрат» (χ 2 теор. ), где ν = N 1 это число степеней свободы, p это доверительная вероятность, задаваемая пользователем, который указывает, насколько ГСЧ должен удовлетворять требованиям равномерного распределения, или p это вероятность того, что экспериментальное значение χ 2 эксп. будет меньше табулированного (теоретического) χ 2 теор. или равно ему .
Таблица 22.2.
Некоторые процентные точки χ 2 -распределения
p = 1% p = 5% p = 25% p = 50% p = 75% p = 95% p = 99% ν = 1 0.00016 0.00393 0.1015 0.4549 1.323 3.841 6.635 ν = 2 0.02010 0.1026 0.5754 1.386 2.773 5.991 9.210 ν = 3 0.1148 0.3518 1.213 2.366 4.108 7.815 11.34 ν = 4 0.2971 0.7107 1.923 3.357 5.385 9.488 13.28 ν = 5 0.5543 1.1455 2.675 4.351 6.626 11.07 15.09 ν = 6 0.8721 1.635 3.455 5.348 7.841 12.59 16.81 ν = 7 1.239 2.167 4.255 6.346 9.037 14.07 18.48 ν = 8 1.646 2.733 5.071 7.344 10.22 15.51 20.09 ν = 9 2.088 3.325 5.899 8.343 11.39 16.92 21.67 ν = 10 2.558 3.940 6.737 9.342 12.55 18.31 23.21 ν = 11 3.053 4.575 7.584 10.34 13.70 19.68 24.72 ν = 12 3.571 5.226 8.438 11.34 14.85 21.03 26.22 ν = 15 5.229 7.261 11.04 14.34 18.25 25.00 30.58 ν = 20 8.260 10.85 15.45 19.34 23.83 31.41 37.57 ν = 30 14.95 18.49 24.48 29.34 34.80 43.77 50.89 ν = 50 29.71 34.76 42.94 49.33 56.33 67.50 76.15 ν > 30 ν + sqrt(2ν ) · x p + 2/3 · x 2 p 2/3 + O (1/sqrt(ν )) x p = 2.33 1.64 0.674 0.00 0.674 1.64 2.33 Приемлемым считают p от 10% до 90% .
Если χ 2 эксп. много больше χ 2 теор. (то есть p велико), то генератор не удовлетворяет требованию равномерного распределения, так как наблюдаемые значения n i слишком далеко уходят от теоретических p i · N и не могут рассматриваться как случайные. Другими словами, устанавливается такой большой доверительный интервал, что ограничения на числа становятся очень нежесткими, требования к числам слабыми. При этом будет наблюдаться очень большая абсолютная погрешность.
Еще Д. Кнут в своей книге «Искусство программирования» заметил, что иметь χ 2 эксп. маленьким тоже, в общем-то, нехорошо, хотя это и кажется, на первый взгляд, замечательно с точки зрения равномерности. Действительно, возьмите ряд чисел 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, они идеальны с точки зрения равномерности, и χ 2 эксп. будет практически нулевым, но вряд ли вы их признаете случайными.
Если χ 2 эксп. много меньше χ 2 теор. (то есть p мало), то генератор не удовлетворяет требованию случайного равномерного распределения, так как наблюдаемые значения n i слишком близки к теоретическим p i · N и не могут рассматриваться как случайные.
А вот если χ 2 эксп. лежит в некотором диапазоне, между двумя значениями χ 2 теор. , которые соответствуют, например, p = 25% и p = 50%, то можно считать, что значения случайных чисел, порождаемые датчиком, вполне являются случайными.
При этом дополнительно надо иметь в виду, что все значения p i · N должны быть достаточно большими, например больше 5 (выяснено эмпирическим путем). Только тогда (при достаточно большой статистической выборке) условия проведения эксперимента можно считать удовлетворительными.
Итак, процедура проверки имеет следующий вид.
Проверки на статистическую независимость
1) Проверка на частоту появления цифры в последовательности
Рассмотрим пример. Случайное число 0.2463389991 состоит из цифр 2463389991, а число 0.5467766618 состоит из цифр 5467766618. Соединяя последовательности цифр, имеем: 24633899915467766618.
Понятно, что теоретическая вероятность p i выпадения i -ой цифры (от 0 до 9) равна 0.1.
2) Проверка появления серий из одинаковых цифр
Обозначим через n L число серий одинаковых подряд цифр длины L . Проверять надо все L от 1 до m , где m это заданное пользователем число: максимально встречающееся число одинаковых цифр в серии.
В примере «24633899915467766618» обнаружены 2 серии длиной в 2 (33 и 77), то есть n 2 = 2 и 2 серии длиной в 3 (999 и 666), то есть n 3 = 2 .
Вероятность появления серии длиной в L равна: p L = 9 · 10 L (теоретическая). То есть вероятность появления серии длиной в один символ равна: p 1 = 0.9 (теоретическая). Вероятность появления серии длиной в два символа равна: p 2 = 0.09 (теоретическая). Вероятность появления серии длиной в три символа равна: p 3 = 0.009 (теоретическая).
Например, вероятность появления серии длиной в один символ равна p L = 0.9 , так как всего может встретиться один символ из 10, а всего символов 9 (ноль не считается). А вероятность того, что подряд встретится два одинаковых символа «XX» равна 0.1 · 0.1 · 9, то есть вероятность 0.1 того, что в первой позиции появится символ «X», умножается на вероятность 0.1 того, что во второй позиции появится такой же символ «X» и умножается на количество таких комбинаций 9.
Частость появления серий подсчитывается по ранее разобранной нами формуле «хи-квадрат» с использованием значений p L .
Примечание: генератор может быть проверен многократно, однако проверки не обладают свойством полноты и не гарантируют, что генератор выдает случайные числа. Например, генератор, выдающий последовательность 12345678912345 , при проверках будет считаться идеальным, что, очевидно, не совсем так.
В заключение отметим, что третья глава книги Дональда Э. Кнута «Искусство программирования» (том 2) полностью посвящена изучению случайных чисел. В ней изучаются различные методы генерирования случайных чисел, статистические критерии случайности, а также преобразование равномерно распределенных случайных чисел в другие типы случайных величин. Изложению этого материала уделено более двухсот страниц.
Детерминированные ГПСЧ
ГПСЧ (PRNG) это генераторы псевдо-случайных чисел. Этот же термин часто используется для описания ГПСБ (PRBG) - генераторов псевдо-случайных бит, а так же различных поточных шифров. ГПСЧ как и поточные шифры состоят из внутреннего состояния (размером от 16 бит до нескольких мегабайт), функции инициализации внутреннего состояния ключом или семенами, функции обновления внутреннего состояния и функции вывода. ГПСЧ подразделяются на простые арифметические, сломанные криптографические и криптостойкие. Их общее предназначение - генерация последовательностей чисел, которые невозможно отличить от случайных.
Никакой детерминированный алгоритм не может генерировать полностью случайные числа, а только лишь аппроксимировать некоторые свойства случайных чисел. Как сказал , «всякий, кто питает слабость к арифметическим методам получения случайных чисел, грешен вне всяких сомнений» .
Любой ГПСЧ с ограниченными ресурсами рано или поздно зацикливается. Длина циклов ГПСЧ зависит от самого генератора и в среднем составляет около 2 (n/2) где n это размер внутреннего состояния в битах, хотя линейные-конгруэнтные генераторы и РЛСО (LFSR) генераторы обладают максимальными циклами порядка 2 n . Если ГПСЧ может сходиться к слишком коротким циклам, такой ГПСЧ становится предсказуемым и является непригодным.
Большинство простых арифметических генераторов хотя и обладают большой скоростью, но страдают от многих серьёзных недостатков:
- Слишком короткий период/периоды
- Последовательные значения не являются независимыми
- Некоторые биты «менее случайны», чем другие
- Неравномерное одномерное распределение
- Обратимость
В частности, алгоритм RANDU, десятилетиями использовавшийся на компьютерах , оказался очень плохим. В результате многие исследования менее надёжны, чем могли бы быть.
ГПСЧ с источником энтропии или ГСЧ
Наравне с существующей необходимостью генерировать легко воспроизводимые последовательности случайных чисел, также существует необходимость генерировать совершенно непредсказуемые или попросту абсолютно случайные числа. Такие генераторы называются «генераторами случайных чисел» («random number generator» ) или сокращённо ГСЧ (RNG). Так как такие генераторы чаще всего применяются для генерации уникальных симметричных и асимметричных ключей для шифрования, они чаще всего строятся из комбинации криптостойкого ГПСЧ и внешнего источника . Таким образом, под ГСЧ теперь принято подразумевать именно криптостойкие ГПСЧ с внешним источником энтропии.
Почти все крупные производители микрочипов поставляют аппаратные ГСЧ с различными источниками энтропии, используя различные методы для их очистки от неизбежных предсказуемостей. Однако на данный момент скорость сбора случайных чисел всеми существующими микрочипами (несколько тысяч бит в секунду) не соответствует быстродействию современных процессоров.
В персональных компьютерах авторы программных ГСЧ используют гораздо более быстрые источники энтропии, такие как шум звуковой карты или значения (processor clock counter) которые легко считываются, например, при помощи инструкции в процессорах Intel. До появления в процессорах возможности считывать значение самого чувствительного к малейшим изменениям окружающей среды счётчика тактов процессора, сбор энтропии являлся наиболее уязвимым местом ГСЧ. Эта проблема до сих пор полностью не разрешена во многих устройствах (например smart-карты), которые таким образом остаются уязвимыми. Многие ГСЧ до сих пор используют традиционные (устаревшие) методы сбора энтропии такие как действия пользователя (движения мыши и т. п.), как например в и Yarrow , или взаимодействие между нитями (threads), как например в Java secure random.
Вот несколько примеров ГСЧ с их источниками энтропии и генераторами:
- /dev/random в / - источник энтропии: , однако собирается только во время аппаратных прерываний; ГПСЧ: LFSR, с хэшированием выхода через ; достоинства: есть во всех Unix-ах, надёжный источник энтропии; недостатки: очень долго «нагревается», может надолго «застревать», либо работает как ГПСЧ (/dev/urandom );
- Yarrow от - источник энтропии: традиционные (устаревшие) методы; ГПСЧ: AES-256 и маленького внутреннего состояния; достоинства: гибкий криптостойкий дизайн; недостатки - долго «нагревается», очень маленькое внутреннее состояние, слишком сильно зависит от криптостойкости выбранных алгоритмов, медленный, применим исключительно для генерации ключей;
- генератор от Леонида Юрьева (Leo Yuriev) - источник энтропии: шум звуковой карты; ГПСЧ: пока не известен; достоинства: скорее всего хороший и быстрый источник энтропии; недостатки - нет независимого, заведомо криптостойкого ГПСЧ, доступен исключительно в виде DLL под Windows;
- Microsoft CryptoAPI - источник энтропии: текущее время, размер hard drive, размер свободной памяти, id процесса и NETBIOS имя компьютера; ГПСЧ: хэш внутреннего состояния размером в 128 бит (хэш присутствует только в 128-битовых версиях Windows); достоинства - встроен в Windows, не «застревает»; недостатки - маленькое внутреннее состояние, легко предсказуем;
- Java SecureRandom - источник энтропии: взаимодействие между нитями (threads); ГПСЧ: хэш внутреннего состояния (1024 бит); достоинства - в Java другого выбора пока нет, большое внутреннее состояние; недостатки: медленный сбор энтропии, хотя в Java другого выбора пока всё равно нет;
- Chaos от Ruptor - источник энтропии: , собирается непрерывно; ГПСЧ: хэширование 4096-битового внутреннего состояния на основе нелинейного варианта Marsaglia генератора; достоинства: пока самый быстрый из всех, большое внутреннее состояние, не «застревает».
Аппаратные ГПСЧ
Кроме устаревших хорошо известных LFSR генераторов широко применявшихся в качестве аппаратных ГПСЧ в прошлом веке к сожалению очень мало известно о современных аппаратных ГПСЧ (поточных шифрах), так как большинство из них разработано для военных целей и держатся в секрете. Почти все существующие коммерческие аппаратные ГПСЧ запатентованы и так же держатся в секрете. Аппаратные ГПСЧ ограничены строгими требованиями к расходуемой памяти (чаще всего использование памяти запрещено), быстродействию (1-2 такта) и площади (несколько сотен FPGA или ASIC ячеек). Из-за таких строгих требований к аппаратным ГПСЧ очень трудно создать криптостойкий генератор, по этому до сих пор все известные аппаратные ГПСЧ были сломаны. Примерами таких генераторов являются Toyocrypt и LILI-128, которые оба являются LFSR генераторами и оба были сломаны с помощью алгебраических атак.
Из-за недостатка хороших аппаратных ГПСЧ производители вынуждены применять имеющиеся под рукой гораздо более медленные, но широко известные блочные шифры как и AES и хэш функции такие как
алгоритм генерации псевдослучайных чисел, называемый алгоритмом BBS (от фамилий авторов - L. Blum, M. Blum, M. Shub) или генератором с квадратичным остатком . Для целей криптографии этот метод предложен в 1986 году.Он заключается в следующем. Вначале выбираются два больших простых 1 Целое положительное число большее единицы называется простым , если оно не делится ни на какое другое число, кроме самого себя и единицы. Подробнее о простых числах см. в "Основные положения теории чисел, используемые в криптографии с открытым ключом" . числа p и q . Числа p и q должны быть оба сравнимы с 3 по модулю 4, то есть при делении p и q на 4 должен получаться одинаковый остаток 3. Далее вычисляется число M = p* q , называемое целым числом Блюма. Затем выбирается другое случайное целое число х , взаимно простое (то есть не имеющее общих делителей, кроме единицы) с М . Вычисляем х0= х 2 mod M . х 0 называется стартовым числом генератора.
На каждом n-м шаге работы генератора вычисляется х n+1 = х n 2 mod M . Результатом n-го шага является один (обычно младший) бит числа х n+1 . Иногда в качестве результата принимают бит чётности, то есть количество единиц в двоичном представлении элемента. Если количество единиц в записи числа четное – бит четности принимается равным 0 , нечетное – бит четности принимается равным 1 .
Например , пусть p = 11, q = 19 (убеждаемся, что 11 mod 4 = 3, 19 mod 4 = 3 ). Тогда M = p* q = 11*19=209 . Выберем х , взаимно простое с М : пусть х = 3 . Вычислим стартовое число генератора х 0 :
х 0 = х 2 mod M = 3 2 mod 209 = 9 mod 209 = 9.
Вычислим первые десять чисел х i по алгоритму BBS . В качестве случайных бит будем брать младший бит в двоичной записи числа х i :
х 1 =9 2 mod 209= 81 mod 209= 81 младший бит: 1 х 2 =81 2 mod 209= 6561 mod 209= 82 младший бит: 0 х 3 =82 2 mod 209= 6724 mod 209= 36 младший бит: 0 х 4 =36 2 mod 209= 1296 mod 209= 42 младший бит: 0 х 5 =42 2 mod 209= 1764 mod 209= 92 младший бит: 0 х 6 =92 2 mod 209= 8464 mod 209= 104 младший бит: 0 х 7 =104 2 mod 209= 10816 mod 209= 157 младший бит: 1 х 8 =157 2 mod 209= 24649 mod 209= 196 младший бит: 0 х 9 =196 2 mod 209= 38416 mod 209= 169 младший бит: 1 х 10 =169 2 mod 209= 28561 mod 209= 137 младший бит: 1 Самым интересным для практических целей свойством этого метода является то, что для получения n-го числа последовательности не нужно вычислять все предыдущие n чисел х i . Оказывается х n можно сразу получить по формуле
Например, вычислим х 10 сразу из х 0 :
В результате действительно получили такое же значение , как и при последовательном вычислении, – 137 . Вычисления кажутся достаточно сложными, однако на самом деле их легко оформить в виде небольшой процедуры или программы и использовать при необходимости.
Возможность "прямого" получения хn позволяет использовать алгоритм BBS при потоковой шифрации, например, для файлов с произвольным доступом или фрагментов файлов с записями базы данных .
Безопасность алгоритма BBS основана на сложности разложения большого числа М на множители. Утверждается, что если М достаточно велико, его можно даже не держать в секрете; до тех пор, пока М не разложено на множители, никто не сможет предсказать выход генератора ПСЧ. Это связано с тем, что задача разложения чисел вида n = pq (р и q - простые числа) на множители является вычислительно очень трудной, если мы знаем только n , а р и q - большие числа, состоящие из нескольких десятков или сотен бит (это так называемая задача факторизации ).
Кроме того, можно доказать, что злоумышленник , зная некоторую последовательность, сгенерированную генератором BBS , не сможет определить ни предыдущие до нее биты, ни следующие. Генератор BBS непредсказуем в левом направлении и в правом направлении . Это свойство очень полезно для целей криптографии и оно также связано с особенностями разложения числа М на множители.
Самым существенным недостатком алгоритма является то, что он недостаточно быстр, что не позволяет использовать его во многих областях, например, при вычислениях в реальном времени, а также, к сожалению, и при потоковом шифровании .
Зато этот алгоритм выдает действительно хорошую последовательность псевдослучайных чисел с большим периодом (при соответствующем выборе исходных параметров), что позволяет использовать его для криптографических целей при генерации ключей для шифрования.
Ключевые термины
Stream cipher – поточный шифр .
Алгоритм BBS – один из методов генерации псевдослучайных чисел. Название алгоритма происходит от фамилий авторов - L. Blum, M. Blum, M. Shub. Алгоритм может использоваться в криптографии. Для вычислений очередного числа x n+1 по алгоритму BBS используется формула х n+1 = х n 2 mod M , где M = pq является произведением двух больших простых p и q .
Генератор псевдослучайных чисел (ГПСЧ) – некоторый алгоритм или устройство, которые создают последовательность битов, внешне похожую на случайную.
Линейный конгруэнтный генератор псевдослучайных чисел – один из простейших ГПСЧ, который для вычисления очередного числа k i использует формулу k i =(a*k i-1 +b)mod c , где а, b, с - некоторые константы , a k i-1 - предыдущее псевдослучайное число .
Метод Фибоначчи с запаздываниями – один из методов генерации псевдослучайных чисел. Может использоваться в криптографии.
Поточный шифр – шифр , который выполняет шифрование входного сообщения по одному биту (или байту) за операцию. Поточный алгоритм шифрования устраняет необходимость разбивать сообщение на целое число блоков. Поточные шифры используются для шифрования данных в реальном времени.
Краткие итоги
Поточный шифр – это шифр , который выполняет шифрование входного сообщения по одному биту (или байту) за операцию. Поточный алгоритм шифрования устраняет необходимость разбивать сообщение на целое число блоков. Таким образом, если передается поток символов, каждый символ может шифроваться и передаваться сразу. Поточные шифры используются для шифрования данных в режиме реального времени.