Автостопом по машинному обучению на Python. Язык программирования Python и пакеты для машинного обучения и Data Mining
Александр Крот, студент ФИВТ МФТИ, мой хороший товарищ и, в недавнем, коллега, запустил цикл статей о практических инструментах интеллектуального анализа больших данных и машинного обучения (Data mining и machine learning).
Уже опубликовано 3 статьи, надеюсь, что дальше будет больше:
1) Введение в машинное обучение с помощью Python и Scikit-Learn
2) Искусство Feature Engineering в машинном обучении
3) Когда данных действительно много: Vowpal Wabbit
В опубликованных статьях делается акцент на практических аспектах работы с инструментами для автоматического анализа данных и с алгоритмами, которые позволяют подготовить данные к эффективному машинному анализу. В частности, приведены примеры кода на языке Python (кстати, именно на Пайтоне мы недавно ) со специализированной библиотекой Scikit-Learn, которые можно быстренько запустить на домашнем компьютере или персональном облаке, чтобы почувствовать вкус больших данных самостоятельно.
Недавно я размышлял о том, как . Знакомство с приведенными инструментами позволит теперь провести практические эксперименты в этом направлении (программу на Пайтоне, кстати, можно запустить и на встроенном в контроллер Линуксе, но вот примеры с перемалыванием гигабайтов данных мобильный процессор навряд ли потянет). И еще кстати, Скала тоже пользуется уважением в среде инженеров, работающих с большими данными , интегрировать такой код будет еще проще.
Традиционно, виртуозное владение любыми инструментами не избавляет от необходимости поиска хорошей задачи, которая с их помощью эффективно решается (если, конечно, вам эту задачу не ставит кто-то другой). Но пространство дополнительных возможностей открывает. В моем представлении, это может выглядеть примерно так: робот (или группа роботов) собирает информацию с сенсоров, отправляет на сервер, где она накапливается и обрабатывается на предмет поиска закономерностей; далее алгоритм будет сверять найденные шаблоны с оперативными значениями сенсоров робота и будет отправлять ему предсказания о наиболее вероятном поведении окружающей среды. Или же на сервере заранее подготавливается база знаний о местности или об определенном типе местности (например, в виде характерных фотографий ландшафта и типичных объектов), а робот сможет использовать эти знания для планирования поведения в оперативной обстановке.
Первую статью утащу для затравки, остальное по ссылкам на Хабре:
Import numpy as np import urllib # url with dataset url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # download the file raw_data = urllib.urlopen(url) # load the CSV file as a numpy matrix dataset = np.loadtxt(raw_data, delimiter="," ) # separate the data from the target attributes X = dataset[:,0 :7 ] y = dataset[:,8 ]
Нормализация данных
Всем хорошо знакомо, что большинство градиентных методов (на которых по-сути и основаны почти все алгоритмы машинного обучения) сильно чуствительны к шкалированию данных. Поэтому перед запуском алгоритмов чаще всего делается либо нормализация , либо так называемая стандартизация . Нормализация предполагает замену номинальных признаков так, чтобы каждый из них лежал в диапазоне от 0 до 1. Стандартизация же подразумевает такую предобработку данных, после которой каждый признак имеет среднее 0 и дисперсию 1. В Scikit-Learn уже есть готовые для этого функции:From sklearn import preprocessing # normalize the data attributes normalized_X = preprocessing.normalize(X) # standardize the data attributes standardized_X = preprocessing.scale(X)
Отбор признаков
Не секрет, что зачастую самым важным при решении задачи является умение правильно отобрать и даже создать признаки. В англоязычной литературе это называется Feature Selection и Feature Engineering . В то время как Future Engineering довольно творческий процесс и полагается больше на интуицию и экспертные знания, для Feature Selection есть уже большое количество готовых алгоритмов. «Древесные» алгоритмы допускают расчета информативности признаков:From sklearn import metrics from sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # display the relative importance of each attribute print(model.feature_importances_)
Все остальные методы так или иначе основаны на эффективном переборе подмножеств признаков с целью найти наилучшее подмножество, на которых построенная модель дает наилучшее качество. Одним из таких алгоритмов перебора является Recursive Feature Elimination алгоритм, который также доступен в библиотеке Scikit-Learn:
From sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression model = LogisticRegression() # create the RFE model and select 3 attributes rfe = RFE(model, 3 ) rfe = rfe.fit(X, y) # summarize the selection of the attributes print(rfe.support_) print(rfe.ranking_)
Построение алгоритма
Как уже было отмечено, в Scikit-Learn реализованы все основные алгоритмы машинного обучения. Рассмотрим некоторые из них.Логистическая регрессия
Чаще всего используется для решения задач классификации (бинарной), но допускается и многоклассовая классификация (так называемый one-vs-all метод). Достоинством этого алгоритма являеся то, что на выходе для каждого обьекта мы имеем вероятсность принадлежности классуFrom sklearn import metrics from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X)
Наивный Байес
Также является одним из самых известных алгоритмов машинного обучения, основной задачей которого является восстановление плотностей распределения данных обучающей выборки. Зачастую этот метод дает хорошее качество в задачах именно многоклассовой классификации.From sklearn import metrics from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
K-ближайших соседей
Метод kNN (k-Nearest Neighbors) часто используется как составная часть более сложного алгоритма классификации. Например, его оценку можно использовать как признак для обьекта. А иногда, простой kNN на хорошо подобранных признаках дает отличное качество. При грамотной настройке параметров (в основном — метрики) алгоритм дает зачастую хорошее качество в задачах регрессииFrom sklearn import metrics from sklearn.neighbors import KNeighborsClassifier # fit a k-nearest neighbor model to the data model = KNeighborsClassifier() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Деревья решений
Classification and Regression Trees (CART) часто используются в задачах, в которых обьекты имеют категориальные признаки и используется для задач регресии и классификации. Очень хорошо деревья подходят для многоклассовой классификацииFrom sklearn import metrics from sklearn.tree import DecisionTreeClassifier # fit a CART model to the data model = DecisionTreeClassifier() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Метод опорных векторов
SVM (Support Vector Machines) является одним из самых известных алгоритмов машинного обучения, применяемых в основном для задачи классификации. Также как и логистическая регрессия, SVM допускает многоклассовую классификацию методом one-vs-all.From sklearn import metrics from sklearn.svm import SVC # fit a SVM model to the data model = SVC() model.fit(X, y) print(model) # make predictions expected = y predicted = model.predict(X) # summarize the fit of the model print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Помимо алгоритмов классификации и регрессии, в Scikit-Learn имеется огромное количество более сложных алгоритмов, в том числе кластеризации, а также реализованные техники построения композиций алгоритмов, в том числе Bagging и Boosting .
Оптимизация параметров алгоритма
Одним из самых сложных этапов в построении действительно эффективных алгоритмов является выбор правильных параметров. Обычно, это делается легче с опытом, но так или иначе приходится делать перебор. К счастью, в Scikit-Learn уже есть немало реализованных для этого функцийДля примера посмотрим на подбор параметра регуляризации, в котором мы по очереди перебирают несколько значений:
Import numpy as np from sklearn.linear_model import Ridge from sklearn.grid_search import GridSearchCV # prepare a range of alpha values to test alphas = np.array() # create and fit a ridge regression model, testing each alpha model = Ridge() grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # summarize the results of the grid search print(grid.best_score_) print(grid.best_estimator_.alpha)
Иногда более эффективным оказывается много раз выбрать случайно параметр из данного отрезка, померить качество алгоритма при данном параметре и выбрать тем самым луйший:
Import numpy as np from scipy.stats import uniform as sp_rand from sklearn.linear_model import Ridge from sklearn.grid_search import RandomizedSearchCV # prepare a uniform distribution to sample for the alpha parameter param_grid = {"alpha" : sp_rand()} # create and fit a ridge regression model, testing random alpha values model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100 ) rsearch.fit(X, y) print(rsearch) # summarize the results of the random parameter search print(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
Мы рассмотрели весь процесс работы с библиотекой Scikit-Learn за исключением вывода результатов обратно в файл, что предлагается сделать читателю в качестве упражнения, потому как одним из достоинств Python (и самой библиотеки Scikit-Learn) по-сравнению с R является отличная документация. В следующих частях мы рассмотрим подробно каждый из разделов, в частности, затронем такую важную вещь как Feauture Engineering .
Я очень надеюсь, что данный материал поможет начинающим Data Scientist"ам как можно скорее приступить к решению задач машинного обучения на практике. В заключение хочу пожелать успехов и терпения тем, кто только начинает участвовать в соревнованиях по машинному обучению!
Каждый эксперт по аналитическим данным задает себе вопрос, какой язык программирования выбрать — R или Python, — пишут ? Для поиска лучшего ответа на этот вопрос в большинстве случаев используется наиболее популярный поисковик Google. Не находя подходящих ответов, потенциальные кандидаты так и не становятся экспертами по технологиям машинного обучения или по аналитическим данным. В данной статье предпринята попытка объяснить специфику языков R и Python для их использования в разработке технологий машинного обучения.
Машинное обучение и наука о данных являются процветающими и постоянно растущими сегментами современных продвинутых технологий, позволяющими решать различные сложные проблемы и задачи в сфере разработок решений и приложений. В этой связи в глобальном масштабе перед аналитиками и экспертами аналитических данных открываются самые широкие возможности применения своих сил и способностей в таких технологиях как искусственный интеллект, IoT и большие данные. Для решения новых сложных задач экспертам и специалистам требуется мощный инструмент обработки огромного массива данных, и для автоматизации задач по анализу, распознаванию и агрегации данных были разработаны разнообразные инструменты и библиотеки машинного обучения.
В развитии библиотек машинного обучения лидерские позиции занимают такие языки программирования как R и Python. Многие эксперты и аналитики тратят время на выбор необходимого языка. Какой же язык программирования более предпочтителен для целей машинного обучения?
В чем сходство R и Python
- Оба языка — R и Python — являются языками программирования с открытым исходным кодом. Огромное число членов сообщества программистов внесло вклад в разработку документации и в развитие данных языков.
- Языки могут быть использованы для анализа данных, аналитики и в проектах машинного обучения.
- Оба имеют продвинутые инструменты для выполнения проектов в сфере науки о данных.
- Оплата труда экспертов по аналитическим данным, предпочитающих работать в R и Python, практически одинакова.
- Текущие версии Python и R — x.x
R и Python – борьба конкурентов
Исторический экскурс:
- В 1991 году Guido Van Rossum, вдохновленный разработками языков C, Modula-3 и ABC, предложил новый язык программирования — Python.
- В 1995 году Ross Ihaka и Robert Gentleman создали язык R, который разрабатывался по аналогии с языком программирования S.
Цели:
- Цель разработки Python – создание программных продуктов, упрощение процесса разработки и обеспечение читаемости кода.
- Тогда как язык R разрабатывался в основном для проведения дружественного к пользователю анализа данных и для решения сложных статистических задач. Это язык, главным образом, статистической ориентированности.
Легкость обучения:
- Благодаря читаемости кода, языку Python легко научиться. Это дружественный для начинающих программистов язык, которому можно научиться, не имея предыдущего опыта в программировании.
- Язык R труден, но, чем дольше использовать этот язык в программировании, тем легче идет обучение и тем выше его результативность в решении сложных статистических формул. Для опытных программистов язык R – это опция go to .
Сообщества:
- Python имеет поддержку различных сообществ, члены которых занимаются развитием языка для перспективных приложений. Программисты и разработчики являются, подобно членам StackOverflow, активными участниками сообщества Рython.
- Язык R также поддерживается членами разнообразных сообществ через листы рассылки, документацию о вкладе пользователей и др. Большинство статистиков, исследователей и экспертов по аналитическим данным принимают активное участие в развитии языка.
Гибкость:
- Python – это язык, акцентирующий внимание на продуктивности, поэтому он достаточно гибок при разработке различных приложений. Для разработки крупномасштабных приложений Python содержит разные модули и библиотеки.
- Язык R также гибок в разработке сложных формул, при проведении статистических тестов, визуализации данных и др. Включает разнообразные и готовые к использованию пакеты.
Применение:
- Python является лидером в разработке приложений. Он используется для поддержки при развитии сайтов и разработке игр, в науке о данных.
- Язык R, главным образом, используется при разработке проектов в области анализа данных, которые сфокусированы на статистике и визуализации.
Оба языка – R и Python – имеют преимущества и недостатки. В большинстве случаев, это специфично-центричные языки, поскольку R сфокусирован на статистике и визуализации, а Рython – на простоте в разработке любого приложения.
Исходя из этого, R может быть использован в основном для исследований в научных институтах, при проведении статистических анализов и визуализации данных. С другой стороны, Python используется для упрощения процесса совершенствования программ, обработке данных и т. д. Язык R может быть очень результативным для статистиков, работающих в сфере анализа данных, а Python лучше подходит для программистов и разработчиков, создающих продукты для экспертов по анализу данных.
Python является отличным языком программирования для реализации по множеству причин. Во-первых, Python имеет понятный синтаксис. Во-вторых, в Python очень просто производить манипуляции с текстом. Python используют большое число людей и организаций во всем мире, поэтому он развивается и хорошо документирован. Язык является кросс-платформенным и пользоваться им можно совершенно бесплатно.
Исполняемый псевдо-код
Интуитивно понятный синтаксис Python зачастую называют исполняемым псевдо-кодом. Установка Python по умолчанию уже включает высокоуровневые типы данных, такие как списки, кортежи, словари, наборы, последовательности и так далее, которые уже нет необходимости реализовывать пользователю. Эти типы данных высокого уровня делают простой реализацию абстрактных понятий. Python позволяет программировать в любом знакомом вам стиле: объектно-ориентированном, процедурном, функциональном и так далее.
В Python просто обрабатывать и манипулировать текстом, что делает его идеальным для обработки нечисловых данных. Есть ряд библиотек для использования Python для доступа к веб-страницам, а интуитивно понятные манипуляции с текстом позволяют легко извлекать данные из HTML -кода.
Python популярен
Язык программирования Python популярен и множество доступных примеров кода делает обучение ему простым и достаточно быстрым. Во-вторых, популярность означает, что есть множество модулей предназначенных для различных приложений.
Python является популярным языком программирования в научных, а также финансовых кругах. Ряд библиотек для научных вычислений, таких как SciPy и NumPy позволяют выполнять операции над векторами и матрицами. Это также делает код еще более читаемым и позволяет писать код, который выглядит как выражения линейной алгебры. Кроме того, научные библиотеки SciPy и NumPy скомпилированы, используя языки низкого уровня (С и Fortran ), что делает делает вычисления при использовании этих инструментов значительно быстрее.
Научные инструменты Python отлично работают в связке с графическим инструментом под названием Matplotlib . Matplotlib может строить двухмерные и трехмерные графики и может работать с большинством типов построений, обычно используемых в научном сообществе.
Python также имеет интерактивную оболочку, которая позволяет просматривать и проверять элементы разрабатываемой программы.
Новый модуль Python , под называнием Pylab , стремится объединить возможности NumPy , SciPy , и Matplotlib в одной среде и установке. На сегодняшний день пакет Pylab пока еще находится в стадии разработки, но за ним большое будущее.
Преимущества и недостатки Python
Люди используют различные языки программирования. Но для многих, язык программирования является просто инструментом для решения какой-то задачи. Python является языком высшего уровня, что позволяет тратить больше времени на осмысление данных и меньше временных на обдумывание того, в каком же виде они должны быть представлены для компьютера.
Единственным реальным недостатком Python является то, что он не так быстро выполняет программный код как, например Java или C . Причиной тому является то, что Python — язык интерпретируемый. Однако существует возможность вызова скомпилированных C -программ из Python . Это позволяет использовать лучшее из различных языков программирования и пошагово разрабатывать программу. Если вы поэкспериментировали над идеей, используя Python и решили, что это именно то, что вы хотите, чтобы было реализовано в готовой системе, то легко можно будет реализовать этот переход от прототипа к рабочей программе. Если программа построена по модульному принципу, то можно сначала удостоверится что то, что вам нужно работает в коде, написанном на Python , а затем, чтобы улучшить скорость выполнения кода, переписать критичные участки на языке C . Библиотека C++ Boost позволяет это с легкостью сделать. Другие инструменты, такие как Cython и PyPy позволяют увеличить производительность работы программы по сравнению с обычным Python .
Если сама реализуемая программой идея является «плохой», то лучше понять это, затратив на написание кода минимум драгоценного времени. Если же идея работает, то всегда можно улучшить производительность, переписав частично критичные участки программного кода.
В последние годы большое число разработчиков, в том числе, имеющих ученые степени, работало над улучшением производительности языка и отдельных его пакетов. Поэтому, не факт, что вы напишите код на C , который будет работать быстрее, чем то, что уже имеется в Python .
Какую версию Python использовать?
В настоящее время одновременно широко применяются различные версии этого, а именно 2.x и 3.x. Третья версия пока еще находится в стадии активной разработки, большинство различных библиотек гарантированно работают на второй версии, поэтому я пользуюсь второй версией, а именно 2.7.8, чего и вам советую. Каких-то прямо уж кардинальных изменений в 3-й версии этого языка программирования нет, поэтому ваш код с минимальными изменениями в будущем, в случае необходимости, можно будет перенести и для использования с третьей версией.
Для установки заходим на официальный сайт: www.python.org/downloads/
выбираем свою операционную систему и скачиваем установщик. Подробно я останавливаться на вопросе установки не буду, поисковики вам с легкостью в этом помогут.
Я на MacOs устанавливал себе версию Python, отличную от той, что была установлена в системе и пакеты через менеджер пакетов Anaconda (кстати, там же есть варианты установки под Windows и Linux ).
Под Windows , говорят, Python ставится с бубном, но сам не пробовал, врать не буду.
NumPy
![]()
NumPy является основным пакетом для научных вычислений в Python . NumPy является расширением языка программирования Python , добавляющим поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых математических функций для работы с этими массивами. Предшественник NumPy , пакет Numeric , был первоначально создан Джимом Хаганином при участии ряда других разработчиков. В 2005 году Трэвис Олифант создал NumPy путем включения функций конкурирующего пакета Numarray в Numeric , произведя при этом обширные изменения.
Для установки в Терминале Linux выполняем:
sudo apt-get update sudo apt-get install python-numpy
sudo apt - get update sudo apt - get install python - numpy |
Простенький код с использованием NumPy который формирует одномерный вектор из 12 чисел от 1 до 12 и преобразует его в трехмерную матрицу:
from numpy import * a = arange(12) a = a.reshape(3,2,2) print a
from numpy import * a = arange (12 ) a = a . reshape (3 , 2 , 2 ) print a |
Результат у меня на компьютере выглядит следующим образом:

Вообще говоря, в Терминале код на Python я выполняю не очень часто, разве чтобы посчитать что-нибудь по-быстрому, как на калькуляторе. Мне нравится работать в IDE PyCharm . Вот так выглядит ее интерфейс при запуске вышеуказанного кода

SciPy
![]() SciPy
— это open-source библиотека с открытым исходным кодом для научных вычислений. Для работы SciPy
требуется, чтобы предварительно был установлен NumPy
, обеспечивающий удобные и быстрые операции с многомерными массивами. Библиотека SciPy
работает с массивами NumPy
, и предоставляет множество удобных и эффективных вычислительных процедур, например, для численного интегрирования и оптимизации. NumPy
и SciPy
просты в использовании, но достаточно мощные для проведения различных научных и технических вычислений.
SciPy
— это open-source библиотека с открытым исходным кодом для научных вычислений. Для работы SciPy
требуется, чтобы предварительно был установлен NumPy
, обеспечивающий удобные и быстрые операции с многомерными массивами. Библиотека SciPy
работает с массивами NumPy
, и предоставляет множество удобных и эффективных вычислительных процедур, например, для численного интегрирования и оптимизации. NumPy
и SciPy
просты в использовании, но достаточно мощные для проведения различных научных и технических вычислений.
Для установки библиотеки SciPy в Linux , выполняем в терминале:
sudo apt-get update sudo apt-get install python-scipy
sudo apt - get update sudo apt - get install python - scipy |
Приведу пример кода для поиска экстремума функции. Результат отображается уже используя пакет matplotlib , рассматриваемый чуть ниже.
import numpy as np from scipy import special, optimize import matplotlib.pyplot as plt f = lambda x: -special.jv(3, x) sol = optimize.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
import numpy as np from scipy import special , optimize f = lambda x : - special . jv (3 , x ) sol = optimize . minimize (f , 1.0 ) x = np . linspace (0 , 10 , 5000 ) plt . plot (x , special . jv (3 , x ) , "-" , sol . x , - sol . fun , "o" ) plt . show () |
Результатом является график с отмеченным экстремумом:

Ради интереса попробуйте реализовать тоже самое на языке C и сравните количество строк кода, требуемых для получения результата. Сколько у вас получилось строк? Сто? Пятьсот? Две тысячи?
Pandas
![]() pandas
— это пакет Python
, предназначенный для обеспечения быстрыми, гибкими, и выразительными структурами данных, упрощающими работу с «относительными» или «помечеными» данными простым и интуитивно понятным способом. pandas
стремится стать основным высокоуровневым строительным блоком для проведения в Python
практического анализа данных, полученных из реального мира. Кроме того, этот пакет претендует стать самым мощным и гибким open-source
инструментом для анализа/обработки данных, доступным в любом языке программирования.
pandas
— это пакет Python
, предназначенный для обеспечения быстрыми, гибкими, и выразительными структурами данных, упрощающими работу с «относительными» или «помечеными» данными простым и интуитивно понятным способом. pandas
стремится стать основным высокоуровневым строительным блоком для проведения в Python
практического анализа данных, полученных из реального мира. Кроме того, этот пакет претендует стать самым мощным и гибким open-source
инструментом для анализа/обработки данных, доступным в любом языке программирования.
Pandas хорошо подходит для работы с различными типами данных:
- Табличные данные со столбцами различных типов, как в таблицах SQL или Excel .
- Упорядоченными и неупорядоченными данными (не обязательно с постоянной частотой) временных рядов.
- Произвольными матричными данными (однородными или разнородными) с помеченными строками и столбцами.
- Любыми другими формами наборов данных наблюдений, либо статистических данных. Данные на самом деле не требуют обязательного наличия метки для того, чтобы быть помещенными в структуру данных pandas .
Для установки пакета pandas выполняем в Терминале Linux :
sudo apt-get update sudo apt-get install python-pandas
sudo apt - get update sudo apt - get install python - pandas |
Простенький код, преобразующий одномерный массив в структуру данных pandas :
import pandas as pd import numpy as np values = np.array() ser = pd.Series(values) print ser
import pandas as pd import numpy as np values = np . array ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd . Series (values ) print ser |
Результатом будет:

matplotlib
![]()
matplotlib является библиотекой графических построений для языка программирования Python и его расширения вычислительной математики NumPy . Библиотека обеспечивает объектно-ориентированный API для встраивания графиков в приложения, используя инструменты GUI общего назначения, такие как WxPython , Qt , или GTK+ . Существует также процедурный pylab -интерфейс напоминающий MATLAB . SciPy использует matplotlib .
Для установки библиотеки matpoltlib в Linux выполните следующие команды:
sudo apt-get update sudo apt-get install python-matplotlib
sudo apt - get update sudo apt - get install python - matplotlib |
Пример кода, использующий библиотеку matplotlib для создания гистограмм:
import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # example data mu = 100 # mean of distribution sigma = 15 # standard deviation of distribution x = mu + sigma * np.random.randn(10000) num_bins = 50 # the histogram of the data n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor="green", alpha=0.5) # add a "best fit" line y = mlab.normpdf(bins, mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Smarts") plt.ylabel("Probability") plt.title(r"Histogram of IQ: $\mu=100$, $\sigma=15$") # Tweak spacing to prevent clipping of ylabel plt.subplots_adjust(left=0.15) plt.show()
import numpy as np import matplotlib . mlab as mlab import matplotlib . pyplot as plt # example data mu = 100 # mean of distribution sigma = 15 # standard deviation of distribution x = mu + sigma * np . random . randn (10000 ) num_bins = 50 # the histogram of the data n , bins , patches = plt . hist (x , num_bins , normed = 1 , facecolor = "green" , alpha = 0.5 ) # add a "best fit" line y = mlab . normpdf (bins , mu , sigma ) plt . plot (bins , y , "r--" ) plt . xlabel ("Smarts" ) plt . ylabel ("Probability" ) plt . title (r "Histogram of IQ: $\mu=100$, $\sigma=15$" ) # Tweak spacing to prevent clipping of ylabel plt . subplots_adjust (left = 0.15 ) plt . show () |
Результатом которого является:
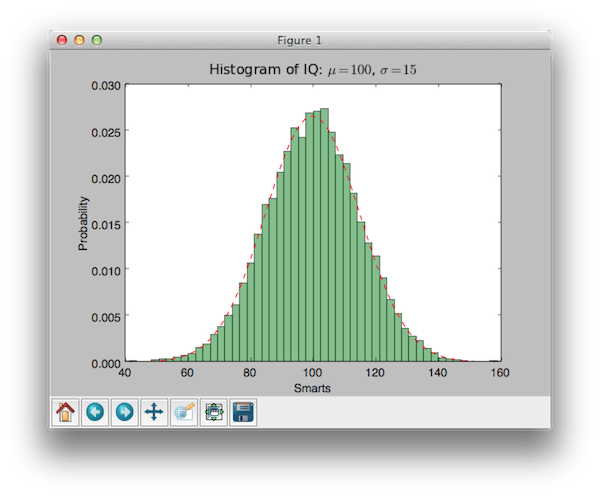
По-моему, очень даже симпатично!
является командной оболочкой для интерактивных вычислений на нескольких языках программирования, первоначально разработанной для языка программирования Python. позволяет расширить возможности представления, добавляет синтаксис оболочке, автодополнение и обширную историю команд. в настоящее время предоставляет следующие возможности:
- Мощные интерактивные оболочки (терминального типа и основанную на Qt ).
- Браузерный редактор с поддержкой кода, текста, математических выражений, встроенных графиков и других возможностей представления.
- Поддерживает интерактивную визуализацию данных и использование инструментов GUI.
- Гибкие, встраиваемые интерпретаторы для работы в собственных проектах.
- Простые в использовании, высокопроизводительные инструменты для параллельных вычислений.
Сайт IPython:
Для установки IPython в Linux, выполняем следующие команды в терминале:
sudo apt-get update sudo pip install ipython
Приведу пример кода, строящего линейную регрессию для некоторого набора данных, имеющихся в пакете scikit-learn :
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model # Load the diabetes dataset diabetes = datasets.load_diabetes() # Use only one feature diabetes_X = diabetes.data[:, np.newaxis] diabetes_X_temp = diabetes_X[:, :, 2] # Split the data into training/testing sets diabetes_X_train = diabetes_X_temp[:-20] diabetes_X_test = diabetes_X_temp[-20:] # Split the targets into training/testing sets diabetes_y_train = diabetes.target[:-20] diabetes_y_test = diabetes.target[-20:] # Create linear regression object regr = linear_model.LinearRegression() # Train the model using the training sets regr.fit(diabetes_X_train, diabetes_y_train) # The coefficients print("Coefficients: \n", regr.coef_) # The mean square error print("Residual sum of squares: %.2f" % np.mean((regr.predict(diabetes_X_test) - diabetes_y_test) ** 2)) # Explained variance score: 1 is perfect prediction print("Variance score: %.2f" % regr.score(diabetes_X_test, diabetes_y_test)) # Plot outputs plt.scatter(diabetes_X_test, diabetes_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color="blue", linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()
import matplotlib . pyplot as plt import numpy as np from sklearn import datasets , linear_model # Load the diabetes dataset diabetes = datasets . load_diabetes () # Use only one feature diabetes_X = diabetes . data [ : , np . newaxis ] |
Всем привет!
В этой статье я расскажу о новом комфортном способе программировать на Python.
Это больше похоже не на программирование, а на создание статей (отчетов/демонстраций/исследований/примеров): среди блоков кода на Python можно вставлять обычный поясняющий текст. Результатом выполнения кода является не только числа и текст (как в случае с консолью при стандартной работе с Python), но еще и графики, диаграммы, картинки…
Примеры документов, которые вы сможете создавать:
Выглядит классно? Хотите создавать такие же документы? Тогда данная статья для вас!
Сначала необходимо установить пакет Anaconda. Что это такое? Это полностью настроенный Python вместе с предустановленным комплектом самых популярных модулей. Anaconda также включает среду JupyterLab, в которой мы и будем создавать документы с Python кодом.
Если Python у вас уже установлен, то сначала удалите его. Сделать это можно через панель «Программы и компоненты» в «Панели управления».
Скачивание

Скачивайте Anaconda для Python 3.6 (Windows 7 и выше) или для Python 2.7 (Windows XP).
Установочный файл весит 500+ MB, так что закачиваться он может достаточно долго.
Установка
Запустите скачанный файл. Откроется окно установщика. На первых двух страницах сразу кликайте «Next». Далее можно выбрать, установить Anaconda только для текущего пользователя компьютера, или для всех.

Важно! В следующем окне нужно указать путь, по которому будет установлена Anaconda. Выбирайте путь, который не содержит папок с пробелами в названии (например, Program Files) и не содержит не английских символов юникода (например, русских букв)!
Игнорирование этих правил может привести к проблемам при работе с разными модулями!
Лично я создал папку Anaconda прямо в корне диска C и указал следующий путь:

На последнем окне будут две галочки. Оставьте все, как есть.
Наконец, начнется установка. Она может занять ~10 минут. Можете спокойно выпить чаю 🙂

Anaconda Navigator
После успешной установки Anaconda запустите программу Anaconda Navigator из меню Пуск. При запуске вы должны увидеть вот этот логотип:
![]()
Затем откроется и сам навигатор. Это отправная точка для работы с Anaconda.

В центральной части окна расположены различные программы, которые входят в пакет Anaconda. Часть их них уже установлена.
В основном мы будем пользоваться «jupyterlab»: именно в ней и создаются красивые документы.
В левой части приведены разделы навигатора. По умолчанию открыт раздел «Home». В разделе «Environments» можно включать/отключать/загружать дополнительные модули Python с помощью удобного интерфейса.
JupyterLab
В разделе навигатора «Home» запустите (кнопка «Launch») программу «jupyterlab» (самая первая в списке).
У вас должен открыться браузер по умолчанию со средой JupyterLab в отдельной вкладке.

Слева отображается содержимое папки C:\Users\<ИМЯ_ВАШЕЙ_УЧЕТНОЙ_ЗАПИСИ> .
Справа открыт файл блокнота «untitled.ipynb». Если справа ничего нет, то вы можете создать новый пустой блокнот, нажав на «+» в левом верхнем углу и выбрав «Notebook Python 3»:

Блокнот
Самое время разобраться с тем, что из себя представляют блокноты.
Обычно мы пишем Python код в файлах с расширением.py , а затем интерпретатор Python их выполняет и выводит данные в консоль. Для удобной работы с такими файлами часто используют среды программирования (IDE). К их числу относится и PyCharm, о котором я рассказывал в статье .
Но есть и другой подход. Он заключается в создании блокнотов (notebook) с расширением ipynb . Блокноты состоят из большого количества блоков. Есть блоки с простым текстом, а есть блоки с кодом на Python.
Попробуйте ввести в первый блок в блокноте какой-нибудь Python код. Например, я создаю переменную, равную сумме чисел 3 и 2:
На следующей строке мы просто пишем название этой переменной. Зачем? Сейчас увидите.
Теперь нужно выполнить этот блок. Для этого нажмите на значок треугольника в панели инструментов над блокнотом или комбинацию клавиш Ctrl + Enter:
Под блоком с Python кодом появился еще один блок, который содержит вывод результатов выполнения предыдущего блока. Сейчас вывод содержит число 5. Это число выводит как раз вторая строчка написанного нами блока.
В обычных средах программирования для достижения такого эффекта нам пришлось бы писать print(a) , а тут вызов этой функции можно опустить и просто написать название переменной, которую мы хотим вывести.
Но выводить значения (числа и текст) переменных (пусть и через функцию) можно и в других средах программирования.
Попробуем сделать что-нибудь посложнее. Например, вывести какую-нибудь картинку.
Создайте новый блок с помощью кнопки в панели инструментов над блокнотом.
В это блоке мы закачиваем логотип Anaconda из сайта Wikimedia и выводим его:
From PIL import Image import requests image_url = "https://upload.wikimedia.org/wikipedia/en/c/cd/Anaconda_Logo.png" im = Image.open(requests.get(image_url, stream=True).raw) im
Результат будет выглядеть так:

Вот на такое обычные среды разработки не способны. А в JupyterLab - запросто!
Теперь давайте попробуем добавить блок с обычным текстом между двумя уже созданными блоками с Python кодом. Для этого щелчком выделите первый блок и добавьте новый блок через кнопку в панели инструментов. Новый блок будет вставлен сразу за первым блоком.
Если вы все сделали правильно, то результат будет выглядеть так:

По умолчанию блоки в JupyterLab предназначены для кода на Python. Для того, чтобы превратить их в текстовые блоки, нужно сменить их тип через панель инструментов. В самом конце панели откройте список и выберите пункт «Markdown»:

Выделенный блок превратится в блок текста. Набранный текст можно оформить курсивом или сделать его жирным . Больше информации по Markdown (средства оформления текста) вы найдете .
Вот так можно оформлять текстовые блоки блокнота:

Экспорт
В JupyterLab можно экспортировать блокнот в самые разные форматы. Для этого в самом верху среды выберите вкладку «Notebook». В открывшемся меню выберите пункт «Export to…» и выберите формат (например, PDF), в который вы хотите преобразовать ваш блокнот.

Вот ссылка на gist с блокнотом из этой статьи.

Управление модулями Python
Включать/отключать/закачивать модули можно из Anaconda Navigator. Для этого в левом меню выберите пункт «Environments»:

По умолчанию отображается список установленных модулей (~217 штук). Среди них есть и такие популярные, как numpy (работа с массивами) или scypi (научные и инженерные расчеты).
Для установки новых пакетов в выпадающем меню над таблицей (там, где написано «Installed») выберите пункт «Not installed»:

Список обновится - автоматически загрузится список неустановленных модулей.
Проставьте галочки рядом с теми модулями, которые хотите загрузить, а затем нажмите на кнопку «Apply» в правом нижнем углу для их загрузки и установки. По завершении процесса вы сможете использовать данные модули в блокнотах.
Выводы
Вы сможете сконцентрироваться на написании алгоритма и немедленной визуализации результатов исполнения кода, вместо того, чтобы возиться со сложными средами для программирования больших программ и консолью, которая может выводить только числа и текст.
Машинное обучение на подъеме, этот термин медленно забрался на территорию так называемых модных слов (buzzword). Это в значительной степени связано с тем, что многие до конца не осознают, что же на самом деле означает этот термин. Благодаря анализу Google Trends (статистике по поисковым запросам), мы можем изучить график и понять, как рос интерес к термину «машинное обучение» в течение последних 5 лет:
Цель
Но эта статья не о популярности машинного обучения . Здесь кратко описаны восемь главных алгоритмов машинного обучения и их использование на практике. Обратите внимание, что все модели реализованы на Python и у вас должно быть хотя бы минимальное знание этого языка программирования. Подробное объяснение каждого раздела содержится в прикрепленных англоязычных видео. Сразу оговоримся, что полным новичкам этот текст покажется сложным, он скорее подходит для продолжающих и продвинутых разработчиков, но главы материала можно использовать как план для построения обучения: что стоит знать, в чем стоит разобраться в первую очередь.
Классификация
Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список:
- Линейная регрессия.
- Логистическая регрессия.
- Деревья решений.
- Метод опорных векторов.
- Метод k-ближайших соседей.
- Алгоритм случайный лес.
- Метод k-средних.
- Метод главных компонент.
Наводим порядок
Вы явно расстроитесь, если при попытке запустить чужой код вдруг окажется, что для корректной работы у вас нет трех необходимых пакетов, да еще и код был запущен в старой версии языка. Поэтому, чтобы сохранить драгоценное время, сразу используйте Python 3.6.2 и импортируйте нужные библиотеки из вставки кода ниже. Данные брались из датасетов Diabetes и Iris из UCI Machine Learning Repository . В конце концов, если вы хотите все это пропустить и сразу посмотреть код, то вот вам ссылка на GitHub-репозиторий .
Import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Линейная регрессия
Возможно, это самый популярный алгоритм машинного обучения на данный момент и в то же время самый недооцененный. Многие специалисты по анализу данных забывают, что из двух алгоритмов с одинаковой производительностью лучше выбирать тот, что проще. Линейная регрессия - это алгоритм контролируемого машинного обучения, который прогнозирует результат, основанный на непрерывных функциях. Линейная регрессия универсальна в том смысле, что она имеет возможность запускаться с одной входной переменной (простая линейная регрессия) или с зависимостью от нескольких переменных (множественная регрессия). Суть этого алгоритма заключается в назначении оптимальных весов для переменных, чтобы создать линию (ax + b), которая будет использоваться для прогнозирования вывода. Посмотрите видео с более наглядным объяснением.
Теперь, когда вы поняли суть линейной регрессии, давайте пойдем дальше и реализуем ее на Python.