Использование вложенных запросов. SELECT - как показываем данные. Создание вложенных sql-запросов. Пример реализации
В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели узнать, кто создал тему "велосипеды", и делали соответствующий запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь мы делали запрос к одной таблице - Темы, а имена авторов тем хранятся в другой таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо сделать еще один запрос - к таблице Пользователи, чтобы узнать его имя:

В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос). Итак, чтобы узнать, кто создал тему "велосипеды", мы сделаем следующий запрос:

То есть, после ключевого слова WHERE , в условие мы записываем еще один запрос. MySQL сначала обрабатывает подзапрос, возвращает id_author=2, и это значение передается в предложение WHERE внешнего запроса.
В одном запросе может быть несколько подзапросов, синтаксис у такого запроса следующий: Обратите внимание, что подзапросы могут выбирать только один столбец, значения которого они будут возвращать внешнему запросу. Попытка выбрать несколько столбцов приведет к ошибке.
Давайте для закрепления составим еще один запрос, узнаем, какие сообщения на форуме оставлял автор темы "велосипеды":
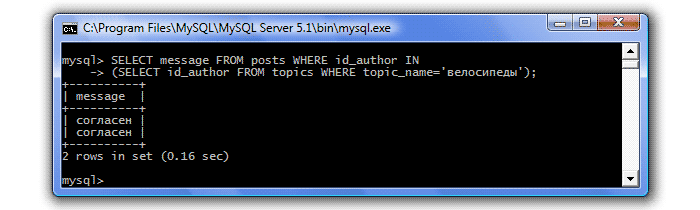
Теперь усложним задачу, узнаем, в каких темах оставлял сообщения автор темы "велосипеды":

Давайте разберемся, как это работает.
- Сначала MySQL выполнит самый глубокий запрос:
- Полученный результат (id_author=2) передаст во внешний запрос, который примет вид:
- Полученный результат (id_topic:4,1) передаст во внешний запрос, который примет вид:
- И выдаст окончательный результат (topic_name: о рыбалке, о рыбалке). Т.е. автор темы "велосипеды" оставлял сообщения в теме "О рыбалке", созданной Сергеем (id=1) и в теме "О рыбалке", созданной Светой (id=4).
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
- Приведенный синтаксис вложенных запросов, скорее наиболее употребительный, но вовсе не единственный. Например,
мы могли бы вместо запроса
написать
Т.е. мы можем использовать любые операторы, используемые с ключевым словом WHERE (их мы изучали в прошлом уроке).
Часто при выборке данных бывает необходимо объединить информацию из нескольких связанных таблиц. Сделать это можно посредством вложенных запросов, либо при помощи соединения с помощью SQL.
Вложенные запросы
В рамках нашего примера, допустим, что нам понадобилось узнать имена узлов, которые посещали сайт www.dom2.ru. Требуемую информацию можно получить запросом:
SELECT hst_name FROM hosts WHERE hst_pcode IN (SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru"));
Рассмотрим этот запрос более пристально. Первый оператор SELECT нужен для выборки имен узлов. Чтобы выбрать требуемые нам имена, в запросе указана секция WHERE, в которой первичный ключ таблицы «Узлы» (hst_pcode) проверяется на принадлежность множеству (оператор IN). Судя по всему, множество для проверки на принадлежность должен вернуть второй оператор SELECT, находящийся в скобках. Рассмотрим его отдельно:
SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru")
Для содержимого таблиц в нашем примере, вложенный запрос вернет следующее множество значений
Соединение с помощью SQL
Как и говорилось выше, одним из способов выборки данных из нескольких таблиц является соединение таблиц с помощью SQL. Основная цель такого соединения - создание нового отношения, которое будет содержать данные из двух или более исходных отношений.
Внутреннее соединение
Рассмотрим пример:
SELECT hst_name, sit_name, vis_timestamp FROM hosts, visits, sites WHERE (hst_pcode = vis_hstcode) AND (vis_sitcode = sit_pcode)
Данный запрос вернет следующие данные
| hst_name | sit_name | vis_timestamp |
| ws1 | www.dom2.ru | 2012-08-01 07:59:58.209028 |
| ws1 | www.vkontakte.ru | 2012-08-01 08:00:10.315083 |
| 1-1 | www.vkontakte.ru | 2012-08-01 08:00:20.025087 |
| 1-2 | www.opennet.ru | 2012-08-01 08:00:26.260159 |
В этом примере из трех таблиц (hosts, visits, sites) выбирается по одному полю и создается новая таблица, в которой будут собраны имена узлов, посещаемых сайтов и время посещений. Представление соединяемых данных регламентируется условиями в операторе WHERE. Видно, что имеется два условия, которые соединяют три таблицы. Поскольку в таблице посещений (visits) вместо имени узла и наименования сайта указаны их идентификаторы, при соединении таблиц мы добавляем условие, чтобы связать по идентификаторам данные и тогда все встанет на свои места. Если по каким-то причинам, вопреки ссылочной целостности в таблице посещений будут находиться записи с идентификатором несуществующего узла или сайта, они не появятся в результирующем наборе данных запроса в этом примере.
Указанный выше пример немного упрощен и из-за немного упрощения теряется наглядность. Более наглядная форма запроса, соединяющего несколько таблиц и возвращающего тот же самый набор данных будет иметь вид
SELECT hst_name, sit_name, vis_timestamp FROM hosts JOIN visits ON (hst_pcode = vis_hstcode) JOIN sites ON (vis_sitcode = sit_pcode);
В запросе присутствует два оператора JOIN… ON. Поскольку «Join» можно перевести как «соединение» или «объединение», этот пример более красноречив. Если попытаться перевести текст SQL-запроса на русский, получится что-то вроде
ВЫБРАТЬ (поля) hst_name, sit_name, vis_timestamp ИЗ (таблицы) hosts СОЕДИНИВ (с таблицей) visits ПО (условию) (hst_pcode = vis_hstcode) СОЕДИНИВ (с таблицей) sites ПО (условию) (vis_sitcode = sit_pcode);
Русские слова в круглых скобках добавлены для облегчения понимания работы запроса. Вы можете использовать любой из вышеперечисленных способов написания запросов.
Внешнее соединение
Использованные выше способы соединения таблиц называются внутреннее соединение (inner join). У такого способа соединения есть недостатки. Например, если у нас не было посещений на один из сайтов, либо один из узлов не совершил ни одного посещения, то в результирующем наборе данных сайт или узел будут отсутствовать. В примере выше видно, что сайт www.yandex.ru отсутствует в данных, равно как и узел 1-3.Иногда это нежелательно и в таких случаях используют внешнее соединение (outer join). Внешнее соединение может быть левым (left join) и правым (right join). Сторона соединения (левая или правая) соответствует таблице, данные из которой будут выбираться полностью. Таким образом, при использовании LEFT JOIN, данные из таблицы слева от оператора JOIN будут выбираться полностью. Закрепим это примером. Допустим, надо выбрать ВСЕ узлы и связанные с ними посещения. Сделать это можно посредством запроса
SELECT hst_name, vis_timestamp FROM hosts LEFT JOIN visits ON (hst_pcode = vis_hstcode);
Обратите внимание на данные, которые вернутся в ответ на запрос
| hst_name | vis_timestamp |
| ws1 | 2012-08-01 07:59:58.209028 |
| ws1 | 2012-08-01 08:00:10.315083 |
| 1-1 | 2012-08-01 08:00:20.025087 |
| 1-2 | 2012-08-01 08:00:26.260159 |
| 1-3 |
Видно, что узлу 1-3 не соответствует ни одно посещение, но он все равно в списке. Аналогичным образом работает RIGHT JOIN. Запрос, который вернет тот же набор данных можно записать с использованием RIGHT JOIN:
SELECT hst_name, vis_timestamp FROM visits RIGHT JOIN hosts ON (hst_pcode = vis_hstcode);
В этом случае, надо сменить LEFT JOIN на RIGHT JOIN и поменять местами таблицы visits и hosts в запросе.
Использование UNION
Иногда бывает нужно получить два списка записей из таблиц в виде одного. Для этой цели может быть использовано ключевое слово UNION, которое позволяет объединить результирующие наборы данных двух запросов в один набор данных. Допустим, надо получить некоторый список, в котором были бы узлы сети и имена сайтов. Таблицы разные, соответственно и запросы будут разными. Как объединить все в один набор данных? Легко, но есть определенные требования к такому «склеиванию» запросов:
§ запросы должны содержать одинаковое число полей;
§ типы данных полей объединяемых запросов так же должны совпадать.
В остальном же, использование UNION не является сложным. Например, чтобы получить список имен узлов и имен сайтов в виде одного набора данных, выполним такой запрос:
SELECT hst_name AS name FROM hosts UNIONSELECT sit_name AS name FROM sites;
При таком подходе возможны проблемы с сортировкой записей. Чтобы список сайтов шел после списка узлов, можно умышленно добавить целочисленное поле, где указывать номер, который будет участвовать в сортировке. Например
SELECT 1 AS level, hst_name AS name FROM hosts UNIONSELECT 2 AS level, sit_name AS name FROM sitesORDER BY level, name;
Условия EXISTS и NOT EXISTS
Иногда бывает необходимо выбрать из таблицы записи, которым соответствуют (или не соответствуют) записи в других таблицах. Допустим, что нам нужен список сайтов, на которые не было посещений. Получить такой список можно запросом
SELECT sit_name FROM sites WHERE ((SELECT COUNT(*) FROM visits WHERE vis_sitcode = sit_pcode) = 0);
Для нашего примера, список будет коротким:
| sit_name |
| www.yandex.ru |
Запрос работает следующим образом:
§ из таблицы sites выбирается код сайта и его наименование;
§ код сайта передается во вложенный запрос, который считает записи с этим кодом в таблице visits;
§ функция COUNT(*) сосчитает записи и вернет их количество, который будет передано в условие;
§ при истинности условия (количество записей равно 0) имя сайта добавляется в список.
Если некоторым этот запрос покажется непонятным, то можно добиться тех же результатов посредством запроса с использованием NOT EXISTS:
SELECT sit_name FROM sites WHERE NOT EXISTS (SELECT vis_pcode FROM visits WHERE vis_sitcode = sit_pcode);
Выражение NOT EXISTS (на мой взгляд) вносит дополнительную ясность и более доступно для понимания. Аналогично работает выражение EXISTS, которое проверяет наличие записей.
Представления (VIEW)
Представления (VIEW) используются для обеспечения возможности сохранения сложного запроса на сервере под указанным именем. Допустим, вам часто приходится запрашивать данные, набирая объемный запрос. Если подойти к проблеме прогрессивно, то можно создать представление. Делается это несложно. Например,
CREATE VIEW show_dom2 ASSELECT hst_name FROM hosts WHERE hst_pcode IN (SELECT vis_hstcode FROM visits, sites WHERE (sit_pcode = vis_sitcode) AND (sit_name LIKE "www.dom2.ru"));
Собственно, всё. Внимательный наблюдатель, наверное, заметил, что по-сути, можно взять запрос и в самом начале добавить слова «CREATE VIEW <имя> AS». Именно по такому принципу можно рекомендовать создание представлений. Создайте запрос, убедитесь в его работоспособности и потом допишите все необходимое, чтобы сохранить этот запрос на сервере как представление. Единственный недостаток использования представлений заключается в том, что некоторые особо сложные приемы написания запросов могут не работать в представлениях. К сожалению, в документации по postgreSQL очень мало сведений о представлениях и однозначно узнать, что можно использовать, а что нет вы сможете методом проб и ошибок. Сохранив запрос на сервере как представление, вы сможете выполнить его сколько угодно раз, запросом типа
SELECT * FROM show_dom2;
Важно отметить, что при выполнении запроса, который выбирает данные из представления - данные выбираются из таблиц посредством запроса, который хранится в представлении. Представление является полностью динамическим и данные, возвращаемые представлением будут актуальными при обновлении данных в таблицах. Удалить представление можно запросом типа
DROP VIEW show_dom2;
Заключение
данные отчет запрос заказ
В данной курсовой работе была разработана база данных "Склад канцтоваров", содержащая всю необходимую информацию о товарах, покупателях, поставщиках и заказах. С помощью моей базы можно без затруднений и специальных знаний вести базу данных, которая позволяет делать все операции с клиентами, заказами, производителями. То есть добавлять, изменять, обновлять, удалять и просматривать все имеющиеся и вводимые данные. На основе базы данных были составлены запросы и отчеты.
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ А
ПРИЛОЖЕНИЕ Б
В лекции обсуждаются вопросы построения и применения подзапросов при извлечении и изменении данных.
Подзапросы
Язык SQL разрешает использовать в других операторах языка DML подзапросы , которые являются внутренними запросами, определяемыми оператором SELECT .
Подзапрос - очень мощное средство языка SQL. Он позволяет строить сложные иерархии запросов, многократно выполняемые в процессе построения результирующего набора или выполнения одного из операторов изменения данных (DELETE , INSERT , UPDATE ).
Условно подзапросы иногда подразделяют на три типа, каждый из которых является сужением предыдущего:
- табличный подзапрос , возвращающий набор строк и столбцов;
- подзапрос строки , возвращающий только одну строку, но, возможно, несколько столбцов (такие подзапросы часто используются во встроенном SQL);
- скалярный подзапрос , возвращающий значение одного столбца в одной строке.
Подзапрос позволяет решать следующие задачи:
- определять набор строк, добавляемый в таблицу на одно выполнение оператора INSERT ;
- определять данные, включаемые в представление, создаваемое оператором CREATE VIEW ;
- определять значения, модифицируемые оператором UPDATE ;
- указывать одно или несколько значений во фразах WHERE и HAVING оператора SELECT ;
- определять во фразе FROM таблицу как результат выполнения подзапроса ;
- применять коррелированные подзапросы . Подзапрос называется коррелированным, если запрос, содержащийся в предикате, имеет ссылку на значение из таблицы (внешней к данному запросу), которая проверяется посредством данного предиката.
Hекоторые СУБД (например, СУБД Oracle) позволяют на основе подзапроса создавать новые таблицы с помощью оператора CREATE TABLE .
Простым примером использования подзапроса может служить следующий оператор:
В данном операторе подзапрос всегда должен возвращать единственное значение, которое будет проверяться в предикате. Если подзапрос вернет более одного значения, то СУБД выдаст сообщение об ошибке выполнения SQL-оператора.
В случае если подзапрос не выберет ни одной строки, то предикат будет равен UNKNOWN , что большинством СУБД интерпретируется как FALSE .
Стандарт определяет запись предиката в форме "значение оператор подзапрос ". Однако некоторые СУБД также позволяют записывать предикат в форме, указывающей подзапрос слева от оператора сравнения.
Например:
Очень часто с подзапросами используются агрегирующие функции, предоставляющие возможность сформулировать условие типа "больше, чем среднее по группе".
Например:
Если результатом подзапроса становится группа строк (это случается всегда, когда условие не гарантирует уникальности значения проверяемого предикатом внутреннего запроса), то следует использовать оператор IN , осуществляющий выбор одного значения из указываемого множества.
Например:
В этом случае предикат принимает значение TRUE , если хотя бы одно из значений, возвращаемых подзапросом , удовлетворяет условию.
Однако применение оператора IN имеет и некоторые смысловые недостатки: в запросе четко не определяется, сколько строк должны быть результатом выполнения запроса. При построении отношений для реальной модели данных это может приводить к некоторой неоднозначности и зависимости от самих данных. В противном случае, если модель данных предполагает в качестве постоянного результата подзапроса наличие только одной строки и, соответственно, использует оператор сравнения = , а структура данных позволяет ввод значений, когда в результате подзапроса будет более одной строки, то при использовании такого SQL-оператора в какой-то момент времени может проявиться ошибка.
Если в запросе участвуют более двух таблиц, то для большей наглядности имена полей иногда квалифицируют именами таблиц, указывая их через точку. Стандарт позволяет не квалифицировать имя поля именем таблицы в том случае, если не возникает неоднозначности (поле сначала ищется в таблице, указанной фразой FROM текущего запроса, затем внешнего запроса и т.д.).
Очень часто вместо записи оператора SELECT с использованием подзапроса можно применять соединения. Однако на практике большинство СУБД подзапросы выполняют более эффективно. Тем не менее, при проектировании комплекса программ с критичными требованиями по быстродействию, разработчик должен проанализировать план выполнения SQL-оператора для конкретной СУБД.
Наиболее продвинутые СУБД, такие как Oracle, предоставляют ряд SQL-операторов, позволяющих оценить производительность выполнения конкретного оператора языка SQL, а также определить уровень оптимизации, применяемый для данного оператора.
Подзапрос может быть указан как в предикате, определяемом фразой WHERE , так и в предикате по группам, определяемом фразой HAVING .
Например:
Коррелированные подзапросы
В операторе SELECT из внутреннего подзапроса можно ссылаться на столбцы внешнего запроса, указанного во фразе SELECT . Такой подзапрос выполняется для каждой строки таблицы, определяя условие ее вхождения в формируемый результирующий набор.
Например:
В данном случае для каждой строки таблицы tbl1 будет проверяться условие, что значение поля f2 совпадает со значением строки таблицы tbl2 , где значение поля f3 равно значению поля f3 внешней таблицы (tbl1 ). Это простейший пример коррелированного подзапроса .
Очень часто требуется, чтобы подзапрос использовал те же данные, что и внешняя таблица. В этом случае обязательно применение алиасов.
Например:
В случае коррелированного подзапроса во фразе HAVING можно использовать только агрегирующие функции, так как каждый раз на момент выполнения подзапроса в качестве проверяемой строки, к значениям которой имеет доступ подзапрос , выступает результат группирования строк на основе агрегирующих функций основного запроса.
Например:
Построение предиката для подзапроса, возвращающего несколько строк
Если в предикате надо сравнить значение с некоторым множеством, то, как было показано выше, можно использовать оператор IN .
Для того чтобы проверить, существуют ли строки, удовлетворяющие конкретному условию подзапроса , применяется оператор EXISTS .
Например:
Этот запрос будет формировать не пустой результирующий набор только в том случае, если в какое-либо значение столбца f4 таблицы была занесена дата, например: "10/11/2003".
Преимущество применения оператора EXISTS с результатами подзапроса состоит в том, что подзапрос может возвращать как множество строк, так и множество столбцов.
При коррелированном подзапросе оператор EXISTS будет вычисляться каждый раз для каждой строки внешнего запроса.
В стандарте SQL-92 не предусмотрено использование в подзапросах , к которым применяется оператор EXISTS агрегирующих функций. Однако некоторые СУБД позволяют такой вид подзапросов .
Для использования результата подзапроса в предикате также применяются операторы ANY и ALL , которые были подробно рассмотрены в предыдущих лекциях.
Приведем пример использования оператора ANY :
Данный оператор определяет, что в результирующий набор будут включены все строки, значение столбца f3 которых присутствует в таблице tbl2 .
Применение подзапросов в операторах изменения данных
К операторам языка DML, кроме оператора SELECT , относятся операторы, позволяющие изменять данные в таблицах. Это оператор INSERT , выполняющий добавление одной или нескольких строк в таблицу, оператор DELETE , удаляющий из таблицы одну или несколько строк, и оператор UPDATE , изменяющий значения столбцов таблицы.
Оператор INSERT
Оператор INSERT
INSERT INTO table_name [ (field .,:) ] { VALUES (value .,:) } | subquery | {DEFAULT VALUES};
Оператор INSERT может добавлять в таблицу как одну, так и несколько строк. Список полей (field .,:) указывает имена полей и порядок занесения в них значений из списка значений, определяемого фразой VALUES , или как результат выполнения подзапроса .
Список, определяемый фразой VALUES , называется конструктором значений таблицы и указывается в круглых скобках через запятую.
Если список полей (field .,:) опущен, то порядок занесения значений будет соответствовать порядку столбцов, указанному в операторе CREATE TABLE при создании данной таблицы.
Если для столбцов, на которые установлено ограничение NOT NULL , не указано добавляемых данных, то СУБД инициирует ошибку выполнения SQL-оператора.
Следующий оператор INSERT демонстрирует копирование строк таблицы tbl2 , выполняемое на основе подзапроса :
INSERT INTO tbl1(f1,f2,f3) (SELECT f1,f2,f3 FROM tbl2);
Очевидно, что количество полей, указываемое списком полей, и типы данных этих полей должны совпадать с количеством полей и их типами данных в конструкторе значений таблицы или в результирующем наборе, формируемом подзапросом .
Оператор DELETE
Оператор DELETE в стандарте SQL-92 имеет следующее формальное описание:
Оператор DELETE используется для удаления из таблицы строк, указанных условием во фразе WHERE (поисковое удаление, searched deletion) или WHERE CURRENT OF (позиционное удаление, positioned deletion).
Позиционное удаление, определяемое фразой WHERE CURRENT OF , удаляя строки из курсора, соответственно удаляет их и из той таблицы базы данных, на базе которой был построен этот курсор.
Если оператор DELETE применяется к какому-либо представлению, то данные удаляются также из созданной на основе последнего таблицы базы данных.
Никогда нельзя забывать, что если фраза WHERE будет отсутствовать или предикат во фразе WHERE будет всегда принимать значение TRUE , то оператор DELETE удалит из таблицы все строки.
Оператор UPDATE
Оператор UPDATE в стандарте SQL-92 имеет следующее формальное описание:
Оператор UPDATE применяется для внесения изменений в данные таблиц.
Выражение expr , используемое для вычисления значения столбца, может быть как простым выражением, так и подзапросом , возвращающим единственное значение. В выражении можно ссылаться на старое значение изменяемого столбца и других столбцов текущей записи.
При вычислении значений столбцов можно применять условное выражение CASE и выражение CAST для приведения типов.
Например:
Условное выражение CASE
Условное выражение CASE позволяет выбрать одно из нескольких значений на основании указываемого условия.
Условное выражение CASE имеет следующее формальное описание:
{ CASE { expr WHEN expr THEN { expr | NULL }} | { WHEN expr THEN { expr | NULL }} [ ELSE { expr | NULL } ] END} | { NULLIF {expr1,expr2) } | {COALESCE (expr .,:) }
Условное выражение CASE может быть записано, соответственно, в четырех формах:
- CASE
с выражениями. Например:
SELECT f1, CASE f3 WHEN "abc" THEN "1_abc" END FROM tbl1;
- CASE
с предикатами. Например:
SELECT f1, CASE WHEN f3= "abc" THEN "1_abc" ELSE f3 END FROM tbl1;
- NULLIF - если выражения, указанные в скобках, не совпадают, то выбирается первое из этих значений, в противном случае устанавливается значение NULL . Например:
- COALESCE
- выбирается первое значение в списке, не равное NULL
. Например:
INSERT INTO tbl1(f1,f2) VALUES (1+ COALESCE(SELECT MAX(f1) FROM tbl1, 0), 100);
Для успешного выполнения оператора UPDATE требуется ряд условий, включающий следующие:
- наличие соответствующих привилегий;
- для представления требуется определение его как изменяемого;
- при изменении представлений применяются ограничения WITH CHECK OPTION или WITH CASCADED CHECK OPTION , установленные при создании этого представления;
- в транзакциях "только чтение" изменение доступно только для временных таблиц;
- выражения, используемые для определения значений, не могут содержать подзапросы с агрегирующими функциями;
- для обновляемого курсора, указанного фразой FOR UPDATE , каждый изменяемый столбец также должен быть определен как FOR UPDATE ;
- в курсоре с фразой ORDER BY нельзя выполнять изменение столбцов, указанных в этой фразе.
- Перевод
- Tutorial
Надо “ SELECT * WHERE a=b FROM c ” или “ SELECT WHERE a=b FROM c ON * ” ?
Если вы похожи на меня, то согласитесь: SQL - это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:


У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” - имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title FROM books WHERE author="Dan Brown";
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM - откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE - какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк , которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author - это “Dan Brown”.
3.3 SELECT - как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid=books.bookid WHERE books.author="Dan Brown";
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы . Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице , которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid - это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 - откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid
Результат соединения можно увидеть по ссылке .
Шаг 2 - какие данные показываем? Нас интересуют только те данные, где автор книги - “Dan Brown”
WHERE books.author="Dan Brown"
Шаг 3 - как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown";
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну . При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count(*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown" GROUP BY members.firstname, members.lastname;
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT "ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock) FROM books GROUP BY author;
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов - использовать подзапросы:
SELECT * FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE author="Robin Sharma";
Результат:
Можно записать как: ["Robin Sharma", "Dan Brown"]
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3);
Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown");
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;
Что дает нам:
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT "ом, мы задаем знаения SET "ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books SET stock=0 WHERE author="Dan Brown";
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books WHERE author="Dan Brown";
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
INSERT INTO x (a,b,c) VALUES (x, y, z);
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
INSERT INTO books (bookid,title,author,published,stock) VALUES (1,"Scion of Ikshvaku","Amish Tripathi","06-22-2015",2), (2,"The Lost Symbol","Dan Brown","07-22-2010",3), (3,"Who Will Cry When You Die?","Robin Sharma","06-15-2006",4), (4,"Inferno","Dan Brown","05-05-2014",3), (5,"The Fault in our Stars","John Green","01-03-2015",3);
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Теги: Добавить метки
Вложенные запросы – это запросы, вызываемые другим, внешним, запросом. Они всегда заключаются в круглые скобки и им обязательно должен присваиваться псевдоним. Некоторые считают вложенный запрос аналогом временных таблиц, однако эти два инструмента имеют ряд отличий, которые мы рассмотрим в данной статье.
Вложенный запрос видит только себя, он не видит внешний запрос. Это значит, что нельзя, например, установить во вложенном запросе условие по значению поля внешнего запроса.
Большинство представленных запросов не имеют какой-либо ценности и могли бы быть выполнены проще. Они приведены только для иллюстрации механизма вложенных запросов.
Вложенные запросы могут использоваться в конструкции ИЗ:
Запрос.
Текст=
"ВЫБРАТЬ
ВложенныйЗапрос.Поле1,
ВложенныйЗапрос.Поле2
ИЗ
(ВЫБРАТЬ
Таблица1.Поле1,
Таблица1.Поле2
ИЗ ТаблицаДанных КАК Таблица1) КАК ВложенныйЗапрос"
;
В том числе в соединениях:
Запрос.
Текст=
"ВЫБРАТЬ
ВложенныйЗапрос.Наименование,
ИЗ
(ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Наименование КАК Наименование
ИЗ
Справочник.Контрагенты КАК Контрагенты) КАК ВложенныйЗапрос
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЧерныйСписок.СрезПоследних КАК ЧерныйСписокСрезПоследних
ПО ВложенныйЗапрос.Ссылка = ЧерныйСписокСрезПоследних.Котрагент"
;
И в условиях запроса со сравнением В или В ИЕРАРХИИ:
Запрос.
Текст=
"ВЫБРАТЬ
ЧерныйСписокСрезПоследних.Состояние
ИЗ
РегистрСведений.ЧерныйСписок.СрезПоследних КАК ЧерныйСписокСрезПоследних
ГДЕ
ЧерныйСписокСрезПоследних.Котрагент В
(ВЫБРАТЬ ПЕРВЫЕ 10
Контрагенты.Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты)"
;
При этом количество выбираемых полей вложенного запроса должно соответствовать количеству операндов в левой части выражения В или В ИЕРАРХИИ.
Существует мнение, что вложенные запросы в сложных конструкциях выполняются платформой 1С нерационально, требуют бОльших ресурсов и времени, нежели те же самые запросы, выполненные иначе, без использования вложенных запросов. Однако в ряде случаев, обойтись без вложенных запросов невозможно.
Вместе с тем, обычно эффективнее работает один большой запрос с вложенными, чем последовательность запросов из модуля.
Практически всегда альтернативой вложенному запросу является использование временных таблиц. Этот инструмент имеет ряд преимуществ:
- Запрос становится более структурированным, его легче читать.
- Результат, загруженный во временную таблицу можно использовать несколько раз, и при этом нет необходимости заново выполнять запрос, чтобы этот результат получить. А вложенный запрос будет каждый раз выполняться заново, излишне загружая ресурсы системы.
Подведем итог: вложенные запросы лучше всего применять в достаточно простых конструкциях, при этом использовать их стоит только тогда, когда по-другому задачу не решить; в сложных запросах лучше использовать временные таблицы.