Как работают поисковые системы? Основные принципы работы поисковых систем в интернете Как работают поисковые системы
Поисковая система — это база данных по определенной информации в интернете. Многие пользователи считают, что как только они вводят запрос в поисковую систему, тут же начинается сканирование всего интернета, но это совсем не так. Сканирование интернета происходит постоянно, многими программами, данные о сайтах заносятся в базу данных, где по определенным критериям все сайты и все их страницы распределяются в различного рода списки и базы данных. То есть это своего рода картотека данных, и поиск происходит не по интернету, а по этой картотеке.
Google — самая популярная поисковая система в мире.
Кроме поисковой системы, компания Google предлагает множество дополнительных сервисов, программ и аппаратного обеспечения, среди которых почтовый сервис , браузер Google Chrome , крупнейшая видеотека youtube и многие другие проекты. Компания Google уверено скупает многие проекты приносящие крупную прибыль. Большинство сервисов направлены не на прямого пользователя, а на заработок в интернете и интегрирована с уклоном на интересы европейских и американских пользователей.
Mail — поисковая система, популярная в основном из-за почтового сервиса.
Имеется множество дополнительных сервисов, ключевым из которых является почта Mail , на данный момент компании Mail принадлежит социальная сеть Одноклассники , собственная сеть «Мой мир», сервис Деньги-mail, множество онлайн игр, три практически одинаковых браузера с различными названиями. Во всех приложениях и сервисах очень много рекламного наполнения. Социальная сеть «ВКонаткте» блокирует прямые переходы в сервисы Mail, агрументируя большим количеством вирусов.
Википедия.
Википедия — поисковая справочная система.
Некоммерческая поисковая система, существующая на частные пожертвования, поэтому не наполняет страницы рекламой. Многоязычный проект, целью которого является создание полной справочной энциклопедии на всех языках мира. У нее нет определенных авторов, заполняется и управляется добровольцами со всех стран мира. Каждый пользователь может как написать, так и отредактировать статью.
Официальная страница — www.wikipedia.org.
Youtube — крупнейшая библиотека видеофайлов.
Видеохостинг с элементами социальной сети, где каждый пользователь может добавить видео. С момента приобретения их компанией Google Ink, отдельная регистрация для ютуба не требуется, достаточно зарегистрироваться в почтовом сервисе Google .
Официальная страница — youtube.com.
Yahoo! — вторая по значимости поисковая система в мире.
Имеются дополнительные сервисы, самым известным из которых является почта Yahoo. В рамках улучшения качества поисковой системы, Yahoo передает данные о пользователях и их запросах в компанию Microsoft. От этих данных формируется представление об интересах пользователей, а так же формируется рынок рекламного наполнения. Поисковая система Yahoo, так же как и , занимается поглощением других компаний, например, Yahoo принадлежат поисковой сервис Altavista и сайт электронной коммерции Alibaba.
Официальная страница — www.yahoo.com.
WDL — цифровая библиотека.
В библиотеке собираются книги предоставляющие культурную ценность в цифровом виде. Основная цель — повышение уровня культурного содержания интернета. Доступ к библиотеке осуществляется бесплатно.
Официальная страница — www.wdl.org/ru/.
Bing — поисковая система от компании Microsoft.
Официальная страница — www.baidu.com.
Поисковые системы России
Рамблер — «проамериканская» поисковая система.
Изначально создавался как медийный интернет-портал. Как и другие многие поисковые системы, имеет сервисы поиска по картинкам, видеофайлы, карты, прогноз погоды, новостной раздел и многое другое. Так же издатели предлагают бесплатный браузер Рамблер-Нихром .
Официальная страница — www.rambler.ru.
Nigma — интеллектуальная поисковая система.
Более удобная поисковая система из-за наличия множества фильтров и настроек. Интерфейс позволяет включать, либо исключать предлагаемые подобные значения в поиске для получения более качественных результатов. Так же, при получении результата поиска позволяет использовать информацию других крупных поисковиков.
Официальная страница — www.nigma.ru.
Aport — каталог товаров онлайн.
В прошлом поисковая система, но впоследсвии того, что разработки и нововведения были прекращены, быстро сдала позиции и . В настоящий момент Апорт является торговой площадкой, на которой представляются товары более 1500 фирм.
Официальная страница — www.aport.ru.
Спутник — национальная поисковая система и интернет-портал.
Создана компанией «Ростелеком». В настоящее время находится в стадии тестирования.
Официальная страница — www.sputnik.ru.
Metabot — развивающаяся поисковая система.
В задачах Metabot стоит создание поисковой системы по всем другим поисковым системам, создавая позиции выдачи результатов с учетом данных всего списка поисковых систем. То есть это поисковая система по поисковым системам.
Официальная страница — www.metabot.ru.
Работа поисковой системы приостановлена.
Официальная страница — www.turtle.ru.
KM — мультипортал.
Изначально сайт являлся мультипорталом с последующим внедрением поисковой системы. Поиск может проводиться как внутри сайта, так и по всем отслеженным сайтам рунета .
Официальная страница — www.km.ru.
Gogo — не работает, перенаправляет на поисковик .
Официальная страница — www.gogo.ru.
Российский мультипортал, не очень популярный, требует доработки. В поисковик включены новости, телевидение, игры, карта.
Официальная страница — www.zoneru.org.
Поисковая система не работает, разработчики предлагают воспользоваться поисковиком .












В последние годы сервисы от «Гугл» и «Яндекс» прочно вошли в нашу жизнь. В этой связи многие наверняка задаются вопросом, что такое поисковая система? Говоря простыми словами, это программная система, предназначенная для поиска информации в World Wide Web. Результаты его обычно представлены в виде списка, часто называемом страницами результатов поиска (SERP). Информация может представлять собой сочетание веб-страниц, изображений и других типов файлов. Некоторые поисковые системы также содержат информацию, доступную в базах данных или открытых каталогах.
В отличие от веб-каталогов, которые поддерживаются только собственными редакторами, поисковики также содержат информацию в режиме реального времени, запуская алгоритм на веб-искателе.
История возникновения
Сами по себе поисковые системы появились ранее всемирной сети - в декабре 1990 года. Первый такой сервис назывался Archie, и он искал по командам содержимое файлов FTP.
Что такое поисковая система в Интернете? До сентября 1993 года World Wide Web была полностью проиндексирована вручную. Существовал список веб-серверов, отредактированный Тимом Бернерс-Ли, который был размещен на веб-сервере CERN. По мере того, как все большее количество серверов выходили в интернет, вышеуказанный сервис не мог успевать обрабатывать такое количество информации.

Одной из первых поисковых систем, основанных на поиске в сети, была WebCrawler, которая вышла в 1994 году. В отличие от своих предшественников, она позволяла пользователям искать любое слово на любой веб-странице. Такой алгоритм с тех пор стал стандартом для всех основных поисковых систем. Это было также первое решение, широко известное публике. Также в 1994 году был запущен сервис Lycos, который впоследствии стал крупным коммерческим проектом.
Вскоре после этого появилось много поисковых машин, и их популярность значительно выросла. К ним можно отнести Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista. Yahoo! был одним из самых популярных способов отыскания интересующих веб-страниц, но его алгоритм поиска работал в своем собственном веб-каталоге, а не в полнотекстовых копиях страниц. Искатели информации также могли просматривать каталог, а не выполнять поиск по ключевым словам.

Новый виток развития
Компания Google приняла идею продажи поисковых запросов в 1998 году, начиная с небольшой компании goto.com. Этот шаг оказал значительное влияние на бизнес SEO, который со временем стал одним из самых прибыльных занятий в Интернете.
Примерно в 2000 году поисковая система «Гугл» стала широко известна. Компания добилась лучших результатов для многих поисков с помощью инноваций под названием PageRank. Этот итерационный алгоритм оценивает веб-страницы на основе их связей с другими сайтами и страницами, исходя из предпосылки, что хорошие или желанные источники часто упоминаются другими. Google также поддерживал минималистский интерфейс для своей поисковой системы. Напротив, многие из конкурентов встроили поисковую систему в веб-портал. На самом деле «Гугл» стала настолько популярной, что появились мошеннические движки, такие как Mystery Seeker. Сегодня существует масса региональных версий этого сервиса, в частности, поисковая система Google.ru, рассчитанная на русскоязычных пользователей.

Как работают эти сервисы?
Как же происходит ранжирование и выдача результатов? Что такое поисковые системы с точки зрения алгоритма действий? Они получают информацию через веб-сканирование с сайта на сайт. Робот или «паук» проверяет стандартное имя файла robots.txt, адресованное ему, перед отправкой определенной информации для индексации. При этом основное внимание уделяется многим факторам, а именно заголовкам, содержимому страницы, JavaScript, каскадным таблицам стилей (CSS), а также стандартной разметке HTML информационного содержимого или метаданным в метатегах HTML.
Индексирование означает связывание слов и других определяемых токенов, найденных на веб-страницах, с их доменными именами и полями на основе HTML. Ассоциации создаются в общедоступной базе данных, доступной для запросов веб-поиска. Запрос от пользователя может быть одним словом. Индекс помогает найти информацию, относящуюся к запросу как можно быстрее.
Некоторые из методов индексирования и кэширования - это коммерческие секреты, тогда как веб-сканирование - это простой процесс посещения всех сайтов на систематической основе.
Между посещениями робота кэшированная версия страницы (часть или весь контент, необходимый для ее отображения), хранящийся в рабочей памяти поисковой системы, быстро отправляется запрашивающему пользователю. Если визит просрочен, поисковик может просто действовать как веб-прокси. В этом случае страница может отличаться от индексов поиска. На кэшированном источнике отображается версия, слова которой были проиндексированы, поэтому он может быть полезен в том случае, если фактическая страница была утеряна.

Высокоуровневая архитектура
Обычно пользователь вводит запрос в поисковую систему в виде нескольких ключевых слов. У индекса уже есть имена сайтов, содержащих данные ключевые слова, и они мгновенно отображаются. Реальная загрузочная нагрузка заключается в создании веб-страниц, которые являются списком результатов поиска. Каждая страница во всем списке должна быть оценена в соответствии с информацией в индексах.
В этом случае верхний элемент результата требует поиска, реконструкции и разметки фрагментов, показывающих контекст из сопоставленных ключевых слов. Это лишь часть обработки каждой веб-страницы в результатах поиска, а дальнейшие страницы (рядом с ней) требуют большей части этой последующей обработки.
Помимо простого отыскания ключевых слов, поисковые системы предлагают свои собственные GUI- или управляемые командами операторы и параметры поиска для того, чтобы уточнить результаты.
Они обеспечивают необходимые элементы управления для пользователя с помощью цикла обратной связи, путем фильтрации и взвешивания при уточнении искомых данных с учетом начальных страниц первых результатов поиска. Например, с 2007 года Google.com позволила отфильтровать полученный список по дате, нажав «Показать инструменты поиска» в крайнем левом столбце на странице исходных результатов, а затем выбрав нужный диапазон дат.

Варьирование запросов
Большинство поисковых систем поддерживают использование логических операторов AND, OR и NOT, чтобы помочь конечным пользователям уточнить запрос. Некоторые операторы предназначены для литералов, которые позволяют пользователю уточнять и расширять условия поиска. Робот ищет слова или фразы точно так же, как и введенные команды. Некоторые поисковые системы предоставляют расширенную функцию отыскания, которая позволяет пользователям определять расстояние между ключевыми словами.
Существует также основанный на концепции поиск, в котором исследование предполагает использование статистического анализа на страницах, содержащих слова или фразы, которые вы ищете. Кроме того, запросы на естественном языке позволяют пользователю вводить вопрос в том же виде, который он задал бы человеку (самый характерный пример - ask.com).
Полезность поисковой системы зависит от релевантности набора результатов, который она выдает. Это могут быть миллионы веб-страниц, которые содержат определенное слово или фразу, но некоторые из них могут быть более релевантными, популярными или авторитетными, чем другие. В большинстве поисковых систем используются методы ранжирования, чтобы обеспечить наилучшие результаты.
Каким образом поисковик решает, какие страницы являются лучшими совпадениями с запросом, и в каком порядке должны отображаться найденные источники, сильно варьируется от одного робота к другому. Эти методы также со временем меняются по мере изменения использования Интернета и развитием новых технологий.
Что такое поисковая система: разновидности
Существует два основных типа поисковой системы. Первая - система предопределенных и иерархически упорядоченных ключевых слов, которыми люди массово ее запрограммировали. Вторая - это система, которая генерирует «инвертированный индекс», анализируя найденные тексты.

Большинство поисковых систем - коммерческие сервисы, поддерживаемые доходами от рекламы, и, таким образом, некоторые из них позволяют рекламодателям иметь рейтинг в отображаемых результатах за определенную плату. Сервисы, которые не принимают деньги за ранжирование, зарабатывают деньги, запуская контекстные объявления рядом с отображенными сайтами. На сегодняшний день продвижение в поисковых системах является одним из наиболее прибыльных заработков в сети.
Какие сервисы распространены наиболее всего?
Google - самая популярная поисковая система в мире с долей рынка 80,52% по состоянию на март 2017 года.
- Google - 80,52%
- Bing - 6,92%
- Baidu - 5,94%
- Yahoo! - 5,35%
Поисковые системы России и стран Восточной Азии
В России и некоторых странах Восточной Азии Google - не самый популярный сервис. Среди российских пользователей поисковая система «Яндекс» лидирует по популярности (61,9%) по сравнению с Google (28,3%). В Китае Baidu является самым популярным сервисом. Поисковый портал Южной Кореи - Naver используется для 70% процентов онлайн-поиска в стране. Также Yahoo! в Японии и Тайвани является наиболее популярным средством для отыскания нужных данных.
Другие известные русские поисковые системы - «Мейл» и «Рамблер». С началом развития рунета они пользовались широкой популярностью, но в настоящее время сильно сдали свои позиции.
Ограничения и критерии поиска
Несмотря на то, что поисковые системы запрограммированы на ранжирование веб-сайтов на основе некоторой их популярности и релевантности, эмпирические исследования указывают на различные политические, экономические и социальные критерии отбора информации, которую они предоставляют. Эти предубеждения могут быть прямым результатом экономических (например, компании, которые рекламируют поисковую систему, могут также стать более популярными в результатах обычного поиска) и политических процессов (например, удаление результатов поиска в соответствии с местными законами). Так, Google не будет отображать некоторые неонацистские сайты во Франции и Германии, где отрицание Холокоста является незаконным.
Христианские, исламские и еврейские поисковые системы
Глобальный рост Интернета и электронных средств массовой информации в мусульманском мире за последнее десятилетие побудил исламских приверженцев на Ближнем Востоке и Азиатском субконтиненте попытаться создать собственные поисковые системы и отфильтрованные порталы, которые позволят пользователям выполнять безопасный поиск.
Такие сервисы содержат фильтры, которые дополнительно классифицируют веб-сайты как «халяль» или «харам» на основе современного экспертного толкования «Закона Ислама».
Портал ImHalal появился в сети в сентябре 2011 года, а Halalgoogling - в июле 2013 года. Они используют фильтры харам, базируясь на алгоритмах от Google и Bing.
Другие, ориентированные на религию поисковые системы - это Jewgle (еврейская версия Google), а также христианская SeekFind.org. Они фильтрует сайты, которые отрицают или унижают их веру.
Поисковые системы (ПС) уже приличное время являются обязательной частью интернета. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и , понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.

Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Анадыри»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. А приучить пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?

Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самый известный и большой каталог в мире имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.

Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

По данным на сентябрь 2015 года , доли поисковых систем в мире распределены следующим образом:
- Google - 69,24 %;
- Bing - 12,26 %;
- Yahoo! - 9,19 %;
- Baidu - 6,48 %;
- AOL - 1,11 %;
- Ask - 0,23 %;
- Excite - 0,00 %

По данным на декабрь 2016 года , доли поисковых систем в Рунете:
- Яндекс - 48,40%
- Google - 45,10%
- Search.Mail.ru - 5,70%
- Rambler - 0,40%
- Bing - 0,30%
- Yahoo - 0,10%

Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.Модуль индексирования.
Данный компонент состоит из трех программ-роботов:Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.

«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.

Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) - комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
«Реферат написать»:

«Купить»:

Но больше всего интересуются…

Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.
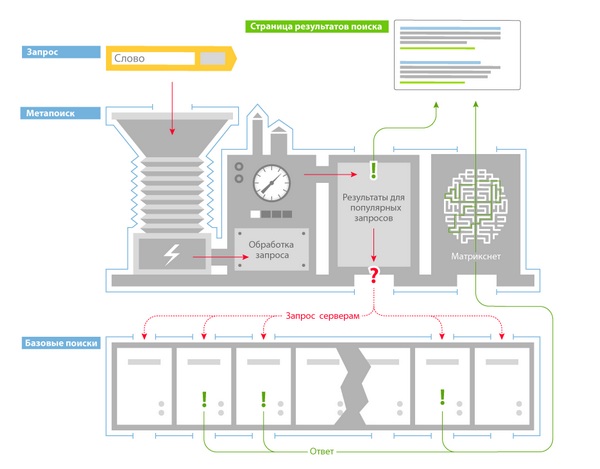
Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.

Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.

Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.
Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.

МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:

Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.
Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».
Интернет необходим многим пользователям для того, чтобы получать ответы на запросы (вопросы), которые они вводят.
Если бы не было поисковых систем, пользователям пришлось бы самостоятельно искать нужные сайты, запоминать их, записывать. Во многих случаях найти «вручную» что-то подходящее было бы весьма сложно, а часто и просто невозможно.
За нас всю эту рутинную работу по поиску, хранению и сортировке информации на сайтах .
Начнем с известных поисковиков Рунета.
Поисковые системы в Интернете на русском
1) Начнем с отечественной поисковой системы. Яндекс работает не только в России, но также работает в Белоруссии и Казахстане, в Украине, в Турции. Также есть Яндекс на английском языке.
2) Поисковик Google пришел к нам из Америки, имеет русскоязычную локализацию:
3)Отечественный поисковик Майл ру, который одновременно представляет социальную сеть ВКонтакте, Одноклассники, также Мой мир, известные Ответы Mail.ru и другие проекты.
4) Интеллектуальная поисковая система
Nigma (Нигма) http://www.nigma.ru/
С 19 сентября 2017 года “интеллектуалка” nigma не работает. Она перестала для её создателей представлять финансовый интерес, они переключились на другой поисковик под названием CocCoc.
5) Известная компания Ростелеком создала поисковую систему Спутник.
Есть поисковик Спутник, разработанный специально для детей, про который я писала .
6) Рамблер был одним из первых отечественных поисковиков:
В мире есть другие известные поисковики:
- Bing,
- Yahoo!,
- Baidu,
- Ecosia,
Попробуем разобраться, как же работает поисковая система, а именно, как происходит индексация сайтов, анализ результатов индексации и формирование поисковой выдачи. Принципы работы поисковых систем примерно одинаковые: поиск информации в Интернете, ее хранение и сортировка для выдачи в ответ на запросы пользователей. А вот алгоритмы, по которым работают поисковики, могут сильно отличаться. Эти алгоритмы держатся в тайне и запрещено ее разглашение.
Введя один и тот же запрос в поисковые строки разных поисковиков, можно получить разные ответы. Причина в том, что все поисковики используют собственные алгоритмы.
Цель поисковиков
В первую очередь нужно знать о том, что поисковики – это коммерческие организации. Их цель – получение прибыли. Прибыль можно получать с контекстной рекламы, других видов рекламы, с продвижения нужных сайтов на верхние строчки выдачи. В общем, способов много.
Зависит от того, какой размер аудитории у него, то есть, сколько человек пользуется данной поисковой системой. Чем больше аудитория, тем большему числу людей будет показываться реклама. Соответственно, стоить эта реклама будет больше. Увеличить аудиторию поисковики могут за счет собственной рекламы, а также привлекая пользователей за счет улучшения качества своих сервисов, алгоритма и удобства поиска.
Самое главное и сложное здесь – это разработка полноценного функционирующего алгоритма поиска, который бы предоставлял релевантные результаты на большинство пользовательских запросов.
Работа поисковика и действия вебмастеров
Каждый поисковик обладает своим собственным алгоритмом, который должен учитывать огромное количество разных факторов при анализе информации и составлении выдачи в ответ на запрос пользователя:
- возраст того или иного сайта,
- характеристики домена сайта,
- качество контента на сайте и его виды,
- особенности навигации и структуры сайта,
- юзабилити (удобство для пользователей),
- поведенческие факторы (поисковик может определить, нашел ли пользователь то, что он искал на сайте или пользователь вернулся снова в поисковик и там опять ищет ответ на тот же запрос)
- и т.д.
Все это нужно именно для того, чтобы выдача по запросу пользователя была максимально релевантной, удовлетворяющей запросы пользователя. При этом алгоритмы поисковиков постоянно меняются, дорабатываются. Как говорится, нет предела совершенству.
С другой стороны, вебмастера и оптимизаторы постоянно изобретают новые способы продвижения своих сайтов, которые далеко не всегда являются честными. Задача разработчиков алгоритма поисковых машин – вносить в него изменения, которые бы не позволяли «плохим» сайтам нечестных оптимизаторов оказываться в ТОПе.
Как работает поисковая система?
Теперь о том, как происходит непосредственная работа поисковой системы. Она состоит как минимум из трех этапов:
- сканирование,
- индексирование,
- ранжирование.
Число сайтов в интернете достигает просто астрономической величины. И каждый сайт – это информация, информационный контент, который создается для читателей (живых людей).
Сканирование
Это блуждание поисковика по Интернету для сбора новой информации, для анализа ссылок и поиска нового контента, который можно использовать для выдачи пользователю в ответ на его запросы. Для сканирования у поисковиков есть специальные роботы, которых называют поисковыми роботами или пауками.
Поисковые роботы – это программы, которые в автоматическом режиме посещают сайты и собирают с них информацию. Сканирование может быть первичным (робот заходит на новый сайт в первый раз). После первичного сбора информации с сайта и занесения его в базу данных поисковика, робот начинает с определенной регулярностью заходить на его страницы. Если произошли какие-то изменения (добавился новый контент, удалился старый), то все эти изменения будут поисковиком зафиксированы.
Главная задача поискового паука – найти новую информацию и отдать ее поисковику на следующий этап обработки, то есть, на индексирование.
Индексирование
Поисковик может искать информацию лишь среди тех сайтов, которые уже занесены в его базу данных (проиндексированы им). Если сканирование – это процесс поиска и сбора информации, которая имеется на том или ином сайте, то индексация – процесс занесения этой информации в базу данных поисковика. На этом этапе поисковик автоматически принимает решение, стоит ли заносить ту или иную информацию в свою базу данных и куда ее заносить, в какой раздел базы данных. Например, Google индексирует практически всю информацию, найденную его роботами в Интернете, а Яндекс более привередлив и индексирует далеко не все.
Для новых сайтов этап индексирования может быть долгим, поэтому посетителей из поисковых систем новые сайты могут ждать долго. А новая информация, которая появляется на старых, раскрученных сайтах, может индексироваться почти мгновенно и практически сразу попадать в «индекс», то есть, в базу данных поисковиков.
Ранжирование
Ранжирование – это выстраивание информации, которая была ранее проиндексирована и занесена в базу того или иного поисковика, по рангу, то есть, какую информацию поисковик будет показывать своим пользователям в первую очередь, а какую информацию помещать «рангом» ниже. Ранжирование можно отнести к этапу обслуживания поисковиком своего клиента – пользователя.
На серверах поисковой системы происходит обработка полученной информации и формирование выдачи по огромному спектру всевозможных запросов. Здесь уже вступают в работу алгоритмы поисковика. Все занесенные в базу сайты классифицируются по тематикам, тематики делятся на группы запросов. По каждой из групп запросов может составляться предварительная выдача, которая впоследствии будет корректироваться.