Перенаправление вывода linux. Как сохранить вывод команды терминала (Bash) в текстовый файл. Как вывести полную информацию о компьютере и сохранить эту информацию в html, pdf
С помощью переназначения устройств ввода/вывода одна программа может направить свой вывод на вход другой или перехватить вывод другой программы, используя его в качестве своих входных данных. Таким образом, имеется возможность передавать информацию от процесса к процессу при минимальных программных издержках. Практически это означает, что для программ, которые используют стандартные входные и выходные устройства, операционная система позволяет:
- выводить сообщения программ не на экран (стандартный выходной поток), а в файл или на принтер (перенаправление вывода);
- читать входные данные не с клавиатуры (стандартный входной поток), а из заранее подготовленного файла (перенаправление ввода);
- передавать сообщения, выводимые одной программой, в качестве входных данных для другой программы (конвейеризация или композиция команд).
Из командной строки эти возможности реализуются следующим образом. Для того, чтобы перенаправить текстовые сообщения, выводимые какой-либо командой из командной строки, в текстовый файл, нужно использовать конструкцию команда > имя_файла. Если при этом заданный для вывода файл уже существовал, то он перезаписывается (старое содержимое теряется), если не существовал создается. Можно также не создавать файл заново, а дописывать информацию, выводимую командой, в конец существующего файла. Для этого команда перенаправления вывода должна быть задана так: команда >> имя_файла . С помощью символа < можно прочитать входные данные для заданной команды не с клавиатуры, а из определенного (заранее подготовленного) файла: команда < имя_файла
Примеры перенаправления ввода/вывода в командной строке
Приведем несколько примеров перенаправления ввода/вывода.
1. Вывод результатов команды ping в файл ping ya.ru > ping.txt
2. Добавление текста справки для команды XCOPY в файл copy.txt: XCOPY /? >> copy.txt
В случае необходимости сообщения об ошибках (стандартный поток ошибок) можно перенаправить в текстовый файл с помощью конструкции команда 2> имя_файла В этом случае стандартный вывод будет производиться на экран. Также имеется возможность информационные сообщения и сообщения об ошибках выводить в один и тот же файл. Делается это следующим образом: команда > имя_файла 2>&1
Например, в приведенной ниже команде стандартный выходной поток и стандартный поток ошибок перенаправляются в файл copy.txt: XCOPY A:\1.txt C: > copy.txt 2>&1
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
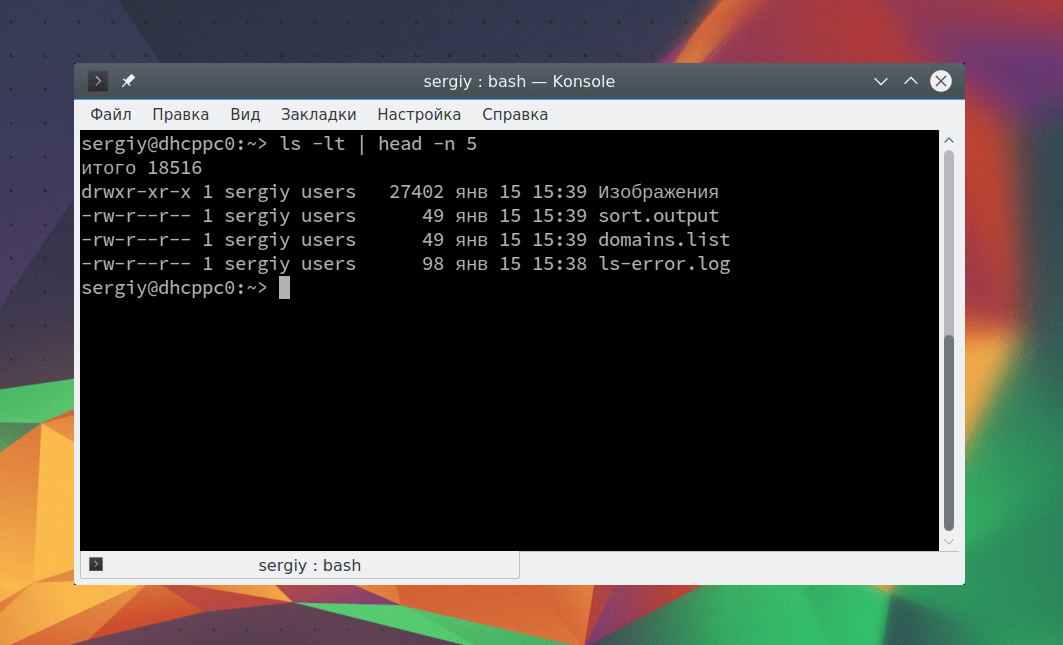
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! Встроенные возможности перенаправления в Linux предоставляют вам широкий набор инструментов, используемых упрощения для всех видов задач. Умение управлять различными потоками ввода-вывода в значительно увеличит производительность, как при разработке сложного программного обеспечения, так и при управлении файлами с помощью командной строки. Ввод и вывод в окружении Linux распределяется между тремя потоками: При взаимодействии пользователя с терминалом стандартный ввод передается через клавиатуру пользователя. Стандартный вывод и стандартная ошибка отображаются на терминале пользователя в виде текста. Все эти три потока называются стандартными потоками. Стандартный входной поток обычно передаёт данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства (например, клавиатуры). Стандартный ввод прекращается по достижении EOF (end-of-file, конец файла). EOF указывает на то, что больше данных для чтения нет. Чтобы увидеть, как работает стандартный ввод, запустите программу cat. Название этого инструмента означает «concatenate» (связать или объединить что-либо). Обычно этот инструмент используется для объединения содержимого двух файлов. При запуске без аргументов cat открывает командную строку и принимает содержание стандартного ввода. Теперь введите несколько цифр: 1 Вводя цифру и нажимая enter, вы отправляете стандартный ввод запущенной программе cat, которая принимает эти данные. В свою очередь, программа cat отображает полученный ввод в стандартном выводе. Пользователь может задать EOF, нажав ctrl-d, после чего программа cat остановится. Стандартный вывод записывает данные, сгенерированные программой. Если стандартный выходной поток не был перенаправлен, он выведет текст в терминал. Попробуйте запустить следующую команду для примера: echo Sent to the terminal through standard output Команда echo без дополнительных опций отображает на экране все аргументы, переданные ей в командной строке. Теперь запустите echo без аргументов: Команда вернёт пустую строку. Этот стандартный поток записывает ошибки, создаваемые программой, которая вышла из строя. Как и стандартный вывод, этот поток отправляет данные в терминал. Рассмотрим пример потока ошибок команды ls. Команда ls отображает содержимое каталогов. Без аргументов эта команда возвращает содержимое текущего каталога. Если указать в качестве аргумента ls имя каталога, команда вернёт его содержимое. Поскольку каталога % не существует, команда вернёт стандартную ошибку: ls: cannot access %: No such file or directory Linux предоставляет специальные команды для перенаправления каждого потока. Эти команды записывают стандартный вывод в файл. Если вывод перенаправлен в несуществующий файл, команда создаст новый файл с таким именем и сохранит в него перенаправленный вывод. Команды с одной угловой скобкой переписывают существующий контент целевого файла: Команды с двойными угловыми скобками не переписывают содержимое целевого файла: Рассмотрим следующий пример: cat > write_to_me.txt В данном примере команда cat используется для записи выходных данных в файл. Просмотрите содержимое write_to_me.txt: cat write_to_me.txt Команда должна вернуть: Снова перенаправьте cat в файл write_to_me.txt и введите три цифры. cat > write_to_me.txt Теперь проверьте содержимое файла. cat write_to_me.txt Команда должна вернуть: Как видите, файл содержит только последние выходные данные, поскольку в команде, перенаправляющей выход, использовалась одна угловая скобка. Теперь попробуйте запустить ту же команду с двумя угловыми скобками: cat >> write_to_me.txt Откройте write_to_me.txt: 1 Команды с двойными угловыми скобками не перезаписывают существующий контент, а дополняют его. Конвейеры (pipes) перенаправляют потоки вывода одной команды на вход другой. При этом данные, передаваемые второй программе, не отображаются в терминале. На экране данные появятся только после обработки второй программой. Конвейеры в Linux представлены вертикальной чертой. Например: Такая команда передаст вывод ls (содержимое текущего каталога) программе less, которая отображает передаваемые ей данные построчно. Как правило, ls выводит содержимое каталогов подряд, не разбивая на строки. Если перенаправить вывод ls в less, то последняя команда разделит вывод на строки. Как видите, конвейер может перенаправить вывод одной команды на вход другой, в отличие от > и >>, которые перенаправляют данные только в файлы. Фильтры – это команды, которые могут изменить перенаправление и вывод конвейера. Примечание
: Фильтры также являются стандартными командами Linux, которые можно использовать и без конвейера. Теперь, когда вы ознакомились с основными понятиями и механизмами перенаправления, рассмотрим несколько базовых примеров их использования. Такой шаблон перенаправляет стандартный вывод команды в файл. ls ~ > root_dir_contents.txt Эта команда передает содержимое root каталога системы в качестве стандартного вывода и записывает вывод в файл root_dir_contents. Это удалит все предыдущее содержимое в файле, так как в команде использована одна угловая скобка. /dev/null – это специальный файл (так называемое «пустое устройство»), который используется для подавления стандартного потока вывода или диагностики, чтобы избежать нежелательного вывода в консоль. Все данные, попадающие в /dev/null, сбрасываются. Перенаправление в /dev/null обычно используется в сценариях оболочки. ls > /dev/null Такая команда сбрасывает стандартный выходной поток, возвращаемый командой ls, передав его в /dev/null. Этот шаблон перенаправляет стандартный поток ошибок команды в файл, перезаписывая его текущее содержимое. mkdir "" 2> mkdir_log.txt Эта команда перенаправит ошибку, вызванную неверным именем каталога, и запишет её в log.txt. Обратите внимание: ошибка по-прежнему отображается в терминале. Этот шаблон перенаправляет стандартный выход команды в файл, не переписывая текущего содержимого файла. echo Written to a new file > data.txt Эта пара команд сначала перенаправляет вводимый пользователем текст в новый файл, а затем вставляет его в существующий файл, не переписывая его содержимого. Этот шаблон перенаправляет стандартный поток ошибок команды в файл, не перезаписывая существующего содержимого файла. Он подходит для создания логов ошибок программы или сервиса, поскольку содержимое лога не будет постоянно обновляться. find "" 2> stderr_log.txt Приведенная выше команда перенаправляет сообщение об ошибке, вызванное неверным аргументом find, в файл stderr_log.txt, а затем добавляет в него сообщение об ошибке, вызванной недействительным аргументом wc. Этот шаблон перенаправляет стандартный выход первой команды на стандартный вход второй команды. find /var lib | grep deb Эта команда ищет в каталоге /var и его подкаталогах имена файлов и расширения deb и возвращает пути к файлам, выделяя шаблон поиска красным цветом. Такой шаблон перенаправляет стандартный вывод команды в файл и переписывает его содержимое, а затем отображает перенаправленный выход в терминале. Если указанного файла не существует, он создает новый файл. В данном шаблоне команда tee, как правило, используется для просмотра вывода программы и одновременного сохранения его в файл. wc /etc/magic | tee magic_count.txt Такая команда передаёт количество символов, строк и слов в файле magic (Linux использует его для определения типов файлов) команде tee, которая отправляет эти данные в терминал и в файл magic_count.txt. Этот шаблон перенаправляет стандартный вывод первой команды и фильтрует ее через следующие две команды, а затем добавляет окончательный результат в файл. ls ~ | grep *tar | tr e E >> ls_log.txt Такая команда отправляет вывод ls для каталога root команде grep. В свою очередь, grep ищет в полученных данных файлы tar. После этого результат grep передаётся команде tr, которая заменит все символы е символом Е. Полученный результат будет добавлен в файл ls_log.txt (если такого файла не существует, команда создаст его автоматически). Функции перенаправления ввода-вывода в Linux сначала кажутся слишком сложными. Однако работа с перенаправлением – один из важнейших навыков системного администратора. Чтобы узнать больше о какой-либо команде, используйте: man command | less Например: Такая команда вернёт полный список команд для tee. Когда вы работаете в терминале, весь вывод команд, естественно, вы видите в реальном времени прямо в окне терминала. Но бывают случаи когда вывод нужно сохранить, дабы поработать с ним позже (проанализировать его, сравнить, и т.п). Так вот, работая в Bash у вас есть возможность перенаправлять отображаемую информацию с окна терминала в текстовый файл. Рассмотрим как это делается. В этом случае весь результат работы любой команды будет записан в текстовый файл, без отображения его на экране. То есть, мы в прямом смысле перенаправим информацию с экрана в файл. Для осуществления этого нужно использовать операторы >
и >>
и путь к файлу в который нужно писать, в конце выполняемой команды. Оператор >
сохранит результат работы команды в указанный файл и, если в нем уже будет находиться какая-либо информация, перезапишет ее. Оператор >>
перенаправит вывод команды в файл, и если в нем также будет находиться информация, новые данные будут добавлены в конец файла. Рассмотрим на примере команды ls
, которая отображает список файлов и папок в указанной директории. Давайте запишем результат ее работы в текстовый файл. Нам нужно написать команду, поставить оператор и указать путь к файлу: Ls > /home/ruslan/пример
Теперь посмотрим, все ли сработало. Для этого можно воспользоваться любым текстовым редактором, какой у вас есть. Также это можно сделать прямо в терминале при помощи команды cat: Cat /home/ruslan/пример
Все работает. Помните, что «>
» перезапишет все данные, которые были до этого в файле, поэтому, если вам нужно дописать что-либо в файл используйте оператор «>>
« Допустим, что после того, как мы перенаправили вывод команды ls
в файл «пример
» мы решили узнать версию ядра системы и также сохранить вывод в тот же файл. Чтобы узнать версию ядра воспользуемся командой uname
и параметром -a
, затем говорим Bash как и куда нужно сохранить результат ее выполнения: Uname -a >> /home/ruslan/пример
Снова проверим результат: Cat /home/ruslan/пример
Как видим, у нас сохранились результаты работы и ls
, и uname
. Не всем и не всегда удобно пользоваться операторами >
и >>
, так как все же лучше когда волнение команд можно наблюдать в реальном времени в окне терминала. В таком случае мы можем воспользоваться командой tee
, которая и отобразит выполнение команд на экране, и сохранит его в файл. Синтаксис ее такой: Команда | tee /путь/к/файлу
Этот вариант подобен оператору >
из предыдущего пункта, то есть при записи в файл, все старые данные будут удалены. Если вам нужно дописать в файл, в конструкцию нужно добавить параметр -a
: Команда | tee -a /путь/к/файлу
Системное администрирование Linux-систем, да и вообще администрирование любой UNIX-подобной системы. Неразрывно связано с работой в командных оболочках. Для опытных системных администраторов такой способ взаимодействия с системой является гораздо более удобным и быстрым, нежели использование графических оболочек и интерфейсов. Конечно, это многим сразу покажется преувеличением, но это неоспоримый факт. Постоянно подтверждаемый на практике. А возможна такая ситуация благодаря некоторым хитростям и инструментам, используемых при работе с командной консолью. И одним из таких инструментов является использование информационных каналов и перенаправления потоков данных для процессов. Следует начать с того, что для каждого процесса система предоставляет в «пользование» как минимум три информационных канала: Строгой принадлежности этих каналов для каждого процесса нет. Сами процессы изначально появившись в системе «не знают» о том, кому и как принадлежат каналы. Они (каналы) являются общесистемным ресурсом. Хотя и устанавливаются ядром от имени процесса. Каналы могут связывать файлы, каналы, связывающие другие процессы, подключения к сети и т. д. В UNIX-подобных системах, согласно модели ввода-вывода. Каждому из информационных каналов присваивается целочисленное значение в качестве номера. Однако для безопасного доступа. к вышеприведённым каналам. За ними зарезервированы постоянные номера - 0, 1 и 2 для STDIN, STDOUT и STDERR соответственно. Во время выполнения процессов считывание входных данных происходит по STDIN. Через клавиатуру, с вывода другого процесса, файла и т. д.. А выходные данные (через STDOUT), а также данные об ошибках (через STDERR). Выводятся на экран, в файл, на вход (уже через STDIN другого процесса) в другую программу. Для изменения направления информационных каналов и связи их с файлами существуют специальные инструкции в виде символов <, > и >>. Так, например инструкцией < можно заставить направить процессу по STDIN содержимое файла. А с помощью инструкции > процесс по STDOUT передаёт выходные данные в файл, при этом заменяется всё содержимое существующего файла целиком. При отсутствии он будет создан. Инструкция >> выполняет то же самое, что и >, но не перезаписывает файл, а дописывает вывод в его конец. Для объединения потоков (т. е. для направления их в один и тот же приёмник) STDOUT и STDERR нужно использовать конструкцию >&. Для направления одного из потоков, например STDERR в отдельное место существует инструкция 2>. Для связывания между собой двух каналов. Например когда нужно вывод одной команды направить на вход другой. Следует использовать для этого инструкцию (символ) «|». Который означает логическую операцию «или». Однако в контексте связывания потоков данная интерпретация не имеет значения, что нередко сбивает с толку новичков. Благодаря таким возможностям можно составлять целые командные конвейеры. Что делает работу в командных оболочках очень эффективной. Направление вывода команды и запись этого вывода в файл /tmp/somemessage:
$ echo “This is a test message” > /tmp/somemessage
В данном случае в качестве команды с выхода которой (по STDOUT) перенаправляются данные в виде текста «This
is
a
test
massage
» является утилита echo. В результате создасться файл /tmp/somemessage, в котором будет запись «This is a test message». Если файл не был создан то он создасться, если создан, то все данные в нем перезапишутся. Если нужно дописать вывод в конец файла, нужно использовать оператор «>>»
$ echo “This is a test message” >> /tmp/somemessage
$ cat /tmp/somemessage
This is a test message
This is a test message
Как видим из примера вторая команда дописала строчку в конец файла. Следующий пример демонстрирует перенаправление входа:
$ mail -s "Mail test" john < /tmp/somemessage
В правой части команды (после символа <) находится файл-источник /tmp/somemesage, содержимое которого перенаправляется в утилиту mail (через STDIN), которая в свою очередь, имеет в качестве собственных параметров заголовок письма и адресата (john). Следующий пример показывает, почему иногда очень полезно разделять потоки из каналов STDIN и STDERR:
$ find / -name core 2> /dev/null
Дело в том, что команда find / -name core будет «сыпать» сообщениями об ошибках, направляя их по-умолчанию в то же место, что и результаты поиска. Т. е. в терминал командной консоли, что существенно затруднит восприятие информации пользователем. Т. к. искомые результаты затеряются среди многочисленных сообщений об ошибках, связанных с режимом доступа. Конструкция 2>/dev/null заставляет утилиту find отправлять сообщения об ошибках (следующие по каналу STDERR с зарезервированным номером 2) на фиктивное устройство /dev/null, оставляя в выводе только результаты поиска.
$ find / -name core > /tmp/corefiles 2> /dev/null
Здесь конструкция > /tmp/corefiles перенаправляет вывод утилиты find (по каналу STDOUT) в файл /tmp/corefiles. Сообщения об ошибках отсеиваются на /dev/null, не попадая в вывод терминала командной консоли. Для связывания между собой разных каналов для разных команд:
$ fsck --help | drep M
M не проверять примонтированные файловые системы Эта команда выведет строку (или строки), содержащие символ «M» из страницы быстрой справки к утилите . Это очень удобно, когда нужно посмотреть только интересующую информацию. В данном случае утилита grep получает вывод (по инструкции |) от команды fsck —help. И далее по шаблону «M» отбрасывает всё лишнее. Если нужно, чтобы следующая в конвейере команда выполнялась только после полного и успешного завершения предыдущей команды, то для этого следует использовать инструкцию &&, например:
$ lpr /tmp/t2 && rm /tmp/page1
Эта команда удалит файл /tmp/page1 только тогда, когда содержимое из него будет отправлено из очереди на печать. Для достижения обратного эффекта, т. е. когда нужно выполнение следующей команды в конвейере только после того, как предыдущая не выполнится (завершится с ошибкой с ненулевым кодом), то следует использовать конструкцию ||. Когда строка кода, включающая слишком длинный конвейер команд тяжело воспринимается, можно разбивать её на логические компоненты по строкам с помощью символа обратной черты «\»:
$ ср --preserve --recursive /etc/* /spare/backup \
|| echo "Make backup error"
Отдельные команды, которые должны выполняться друг за другом можно объединять в одну строку, разделяя их символом двоеточия «;»: Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter
.

Использование тоннелей


Выводы
Потоки ввода-вывода
Стандартный ввод
2
3
ctrl-dСтандартный вывод
Стандартная ошибка
Перенаправление потоков
a
b
c
ctrl-d
1
2
3
ctrl-d
a
b
c
ctrl-d
2
3
a
b
cКонвейеры
Фильтры
Примеры перенаправления ввода-вывода
команда > файл
команда > /dev/null
команда 2 > файл
команда >> файл
echo Appended to an existing file"s contents >> data.txtкоманда 2>>файл
wc "" 2>> stderr_log.txtкоманда | команда
команда | tee файл
команда | команда | команда >> файл
Заключение
Вариант 1: только перенаправляем вывод терминала в файл


Вариант 2: перенаправляем вывод в файл и отображаем его на экране

Немного теории
Вывод в файл
Получение данных из файла
Другие примеры