Двоичный код удовлетворяющий условию фано. Условие фано
Здравствуйте! Меня зовут Александр Георгиевич и я являюсь московским профессиональным репетитором по информатике и программированию. Вам попалась задача, связанная с кодированием и , и вы запутались в алгоритме ее решения? Вам срочно нужно познакомиться с условием Фано , а также записаться ко мне на индивидуальные уроки. На своих уроках я акцентирую внимание на решении тематических простых и сложных упражнений.
В чем смысл прямого условия Фано?
Условие Фано названо в честь его создателя, итальянско-американского ученого Роберта Фано. Условие является необходимым в теории кодирования при построении самотерминирующегося кода. Учитывая другую терминологию, такой код называется префиксным.
Сформулировать данное условие можно следующим образом: «ни одно кодовое слово не может выступать в качестве начала любого другого кодового слова ».
С математической точки зрения условие можно сформулировать следующим образом: «если код содержит слово B, то для любой непустой строки C слова BC не существует в коде ».
В чем смысл обратного условия Фано?
Существует также и обратное правило Фано, формулировка которого звучит следующим образом: «ни одно кодовое слово не может выступать в качестве окончания любого другого кодового слова ».
С математической точки зрения обратное условие можно сформулировать следующим образом: «если код содержит слово B, то для любой непустой строки C слова CB не существует в коде ».
Практическое применение условия Фано
Рассмотрим телефонные номера в традиционной телефонии. Если уже существует номер «102», то номер «1029876» попросту не будет выдан. В случае набора первых трех цифр АТС перестает распознавать и принимать все остальные цифры, соединяя с абонентом по номеру 102. Однако это правило не является действительным для операторов мобильной связи. Связано это с тем, что для набора номера необходимо нажатие соответствующей клавиши, которой, в основном, является клавиша с изображением зеленой телефонной трубки. По этой причине, номера «102», «1020» и «1029876» могут существовать и быть закрепленными за разными адресатами.
Условие задачи: дана последовательность, которая состоит из букв «A», «B», «C», «D» и «E». Для кодирования приведенной последовательности применяется неравномерный двоичный код, при помощи которого можно осуществить однозначное декодирование.
Вопрос : есть ли возможность для одного из символов сократить длину кодового слова таким образом, чтобы сохранить возможность однозначного декодирования? При этом коды остальных символов должны остаться неизменными.
Решение : для того, чтобы сохранилась возможность декодирования, достаточным является соблюдение прямого или обратного условия Фано . Проведем последовательную проверку вариантов 1, 3 и 4. В случае если ни один из вариантов не подойдет, правильным ответом будет вариант 2 (не представляется возможным).
Вариант 1. Код: A - 00, B - 01, C - 011, D - 101, и E - 111. Прямое условие Фано не выполняется: код символа «B» совпадает с началом кода символа «C». Обратное правило Фано не выполняется: код символа «B» совпадает с окончанием кода символа «D». Вариант не является подходящим.
Вариант 3. Код: A - 00, B - 010, C - 01, D - 101, и E - 111. Прямое условие Фано не выполняется: код символа «C» совпадает с началом кода символа «B». Обратное условие также не выполняется: код символа «C» совпадает с окончанием кода символа «D». Вариант не является подходящим.
Вариант 4. Код: A - 00, B - 010, C - 011, D - 01, и E - 111. Прямое условие Фано не выполняется: код символа «D» совпадает с началом кода символов «B» и «C». Однако наблюдается выполнение обратного правила Фано: код символа «D» не совпадает с окончанием кода всех остальных символов. По этой причине, вариант является подходящим.
После проверки вариантов решения задачи на соответствие прямому и обратному условию Фано , было установлено, что правильным является вариант 4.
Ответ : 4
А сейчас я вам предлагаю ознакомиться с мультимедийным решением задачи, которая была предложена в демонстрационном варианте ЕГЭ по информатике и ИКТ. Кстати, данная задача относится к типу задач, решаемых с использованием условия Фано .
Остались вопросы?
Если после прочтения данной публикации у вас все равно остались какие-то вопросы, непонимания или вы хотите закрепить пройденный материал практическими решениями, то звоните и записывайтесь ко мне на частные уроки по информатике и ИКТ.
Урок посвящен тому, как решать 5 задание ЕГЭ по информатике
5-я тема характеризуется, как задания базового уровня сложности, время выполнения – примерно 2 минуты, максимальный балл — 1
- Кодирование - это представление информации в форме, удобной для её хранения, передачи и обработки. Правило преобразования информации к такому представлению называется кодом .
- Кодирование бывает равномерным и неравномерным :
- при равномерном кодировании всем символам соответствуют коды одинаковой длины;
- при неравномерном кодировании разным символам соответствуют коды разной длины, это затрудняет декодирование.
Пример:
Зашифруем буквы А, Б, В, Г при помощи двоичного кодирования равномерным кодом и посчитаем количество возможных сообщений:
Таким образом, мы получили равномерный код
, т.к. длина каждого кодового слова одинакова для всех кодов
(2).
Кодирование и расшифровка сообщений
Декодирование (расшифровка) - это восстановление сообщения из последовательности кодов.
Для решения задач с декодированием, необходимо знать условие Фано:
Условие Фано: ни одно кодовое слово не должно являться началом другого кодового слова (что обеспечивает однозначное декодирование сообщений с начала)
Префиксный код - это код, в котором ни одно кодовое слово не совпадает с началом другого кодового слова. Сообщения при использовании такого кода декодируются однозначно.

Однозначное декодирование обеспечивается:



Решение 5 заданий ЕГЭ
ЕГЭ 5.1: Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0 , 1 , 2 , 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления).
Закодируйте последовательность букв ВОДОПАД таким способом и результат запишите восьмеричным кодом.
✍ Решение:
- Переведем числа в двоичные коды и поставим их в соответствие нашим буквам:
Результат: 22162
Решение ЕГЭ данного задания по информатике, видео:
Рассмотрим еще разбор 5 задания ЕГЭ:
ЕГЭ 5.2: Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух бит, для некоторых - из трех). Эти коды представлены в таблице:
| a | b | c | d | e |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
Какой набор букв закодирован двоичной строкой 1100000100110 ?
✍ Решение:
- Во-первых, проверяем условие Фано: никакое кодовое слово не является началом другого кодового слова. Условие верно.
- Код разбиваем слева направо согласно данным, представленным в таблице. Затем переведём его в буквы:
✎ 1 вариант решения:
Результат: b a c d e.
✎ 2 вариант решения:
 110
000 01
001 10
110
000 01
001 10
Результат: b a c d e.
Кроме того, вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
Решим следующее 5 задание:
ЕГЭ 5.3:
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4 , и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23 , то получим последовательность 0010100110).
Определите, какое число передавалось по каналу в виде 01100010100100100110 .
✍ Решение:
- Рассмотрим пример из условия задачи:
Ответ: 6 5 4 3
Вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
ЕГЭ 5.4:
Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0 , для буквы К - кодовое слово 10 .
Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
✍ Решение:
✎ 1 вариант решения основан на логических умозаключениях:
- Найдём самые короткие возможные кодовые слова для всех букв.
- Кодовые слова 01 и 00 использовать нельзя, так как тогда нарушается условие Фано (начинаются с 0, а 0 — это Н ).
- Начнем с двухразрядных кодовых слов. Возьмем для буквы Л кодовое слово 11 . Тогда для четвёртой буквы нельзя подобрать кодовое слово, не нарушая условие Фано (если потом взять 110 или 111, то они начинаются с 11).
- Значит, надо использовать трёхзначные кодовые слова. Закодируем буквы Л и М кодовыми словами 110 и 111 . Условие Фано соблюдается.
✎ 2 вариант решения :
 (Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
(Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
Ответ: 9
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 2 (под редакцией Крылова С.С., Чуркиной Т.Е.):
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А, Б, В используются такие кодовые слова: А: 101010 , Б: 011011 , В: 01000 .
Г, при котором код будет допускать однозначное декодирование. наименьшим числовым значением.
✍ Решение:
- Наименьшие коды могли бы выглядеть, как 0 и 1 (одноразрядные). Но это не удовлетворяло бы условию Фано (А начинается с единицы — 101010 , Б начинается с нуля — 011011 ).
- Следующим наименьшим кодом было бы двухбуквенное слово 00 . Так как оно не является префиксом ни одного из представленных кодовых слов, то Г = 00 .
Результат: 00
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 16 (под редакцией Крылова С.С., Чуркиной Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 01 , Б — 00 , В — 11 , Г — 100 .
Укажите, каким кодовым словом должна быть закодирована буква Д.
Длина
этого кодового слова должна быть наименьшей
из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
✍ Решение:
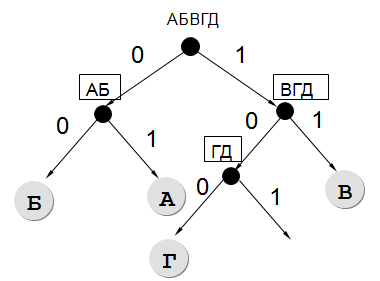
Результат: 101
Подробней разбор урока можно посмотреть на видео ЕГЭ по информатике 2017:
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 17 (Крылов С.С., Чуркина Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д и Е, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 0 , Б — 111 , В — 11001 , Г — 11000 , Д — 10 .
Укажите, каким кодовым словом должна быть закодирована буква Е. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
✍ Решение:
 1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
Результат: 1101
Более подробное решение данного задания представлено в видеоуроке:
5 задание. Демоверсия ЕГЭ 2018 информатика (ФИПИ):
По каналу связи передаются шифрованные сообщения, содержащие только десять букв: А, Б, Е, И, К, Л, Р, С, Т, У. Для передачи используется неравномерный двоичный код. Для девяти букв используются кодовые слова.
Укажите кратчайшее кодовое слово для буквы Б
, при котором код будет удовлетворять условию Фано.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.
✍ Решение:
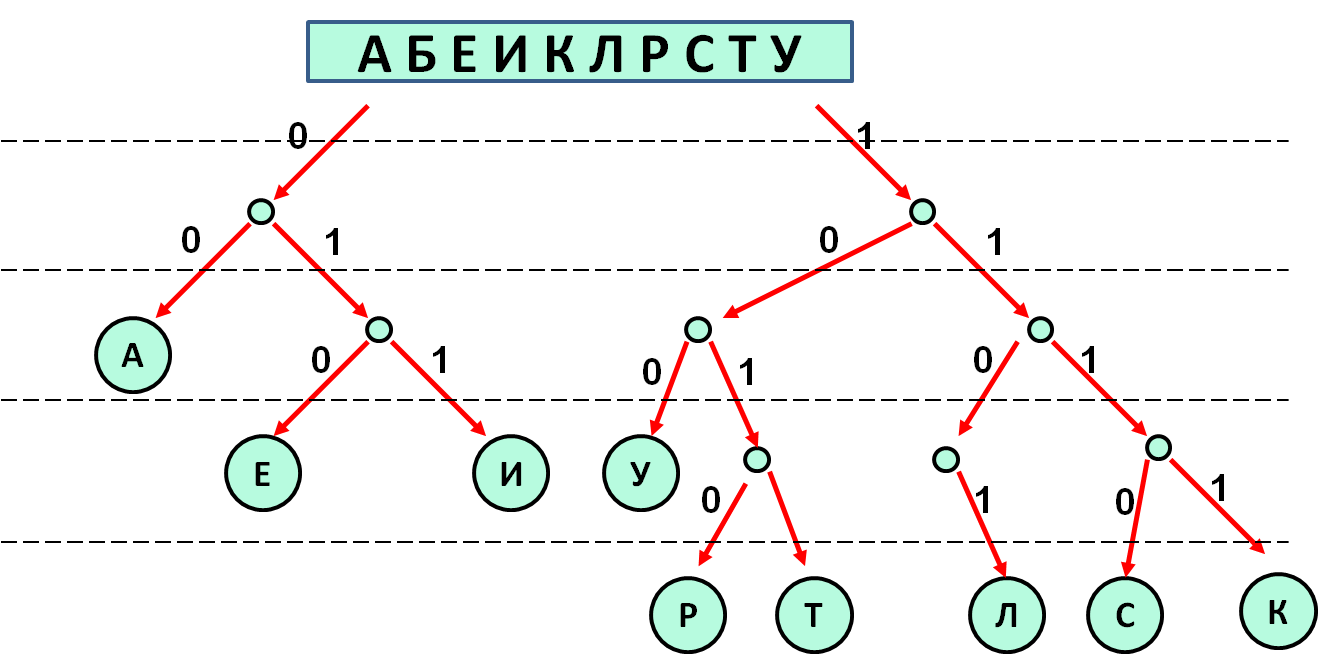
Результат: 1100
Подробное решение данного 5 задания из демоверсии ЕГЭ 2018 года смотрите на видео:
Задание 5_9. Типовые экзаменационные варианты 2017. Вариант 4 (Крылов С.С., Чуркина Т.Е.):
По каналу связи передаются шифрованные сообщения, содержащие только четыре букв: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А , Б , В используются кодовые слова:
А: 00011 Б: 111 В: 1010
Укажите кратчайшее кодовое слово для буквы Г
, при котором код будет допускать однозначное декодирование.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.
✍ Решение:

Результат: 00
Задание 5_10. Тренировочный вариант №3 от 01.10.2018 (ФИПИ):
По каналу связи передаются сообщения, содержащие только буквы: А, Е, Д, К, М, Р ; для передачи используется двоичный код, удовлетворяющий условию Фано. Известно, что используются следующие коды:
Е – 000 Д – 10 К – 111
Укажите наименьшую возможную длину закодированного сообщения ДЕДМАКАР
.
В ответе напишите число – количество бит.
✍ Решение:
 Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Результат: 20
Смотрите виде решения задания:
3. Коды без разделителя. Условие Фано
Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответ на следующий вопрос: возможно ли такое кодирование без использования разделительных знаков?
Суть этой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из сообщения каждого отдельного знака (то есть декодирование) оказывается однозначным без специальных указателей разделения знаков.
Наиболее простыми и употребимыми кодами без разделителя являются так называемые префиксные коды , которые удовлетворяют следующему условию –условию Фано :Сообщение, закодированное с использованием неравномерного кода может быть однозначно декодировано, если никакой из кодов в данном сообщении не совпадает с префиксом * (началом) какого-либо иного более длинного кода.
Например, если имеется код 110, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр.
Если условие Фано выполняется, то при прочтении (декодировании, расшифровке) закодированного сообщения путем сопоставления с таблицей кодов всегда можно точно указать, где заканчивается один код и начинается другой.
Пример 1 . Являются ли коды, представленные втабл. 4,префиксными? Коды, представленные в табл. 4, не являются префиксными. См., например, коды букв «О» и «Е», «А» и «Н», «С» и «М», «Д» и «Ч».
Пример 2 . Имеется таблица префиксных кодов (табл. 6). Требуется декодировать следующее сообщение, закодированное с использованием этой приведенной кодовой таблицы:
00100010000111010101110000110
Табл. 6. Таблица префиксных кодов
Декодирование производится циклическим повторением следующих действий:
«Отрезать» от текущего сообщения крайний слева символ, присоединить его справа к рабочему (текущему) кодовому слову;
сравнить текущее кодовое слово с кодовой таблицей; если совпадения нет, вернуться к пункту 1.
С помощью кодовой таблицы текущему кодовому слову поставить в соответствие символ первичного алфавита;
Проверить, имеются ли еще знаки в закодированном сообщении; если да, то перейти к пункту 1.
Применение данного алгоритма к предложенному выше закодированному сообщению дает:
00100010000111010101110000110
Таким образом, доведя процедуру декодирования до конца, можно получить сообщение: «мама мыла раму».
Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким, поскольку нет необходимости передавать разделители знаков.
Однако условие Фано не устанавливает конкретного способа формирования префиксного кода, оставляя поле для деятельности по разработке наилучшего из возможных префиксных кодов.
4. Префиксный код Шеннона–Фано
Рассмотрим вариант кодирования, который был предложен в 1948 – 1949 гг. независимо К. Шенноном и Р. Фано.
Рассмотрим схему кодирования (как она строится) Шеннона–Фано на следующем примере .
Пусть
имеется первичный алфавит
,
состоящий из шести знаков: ,
где
,
где .
Пусть вероятности появления этих знаков
в сообщениях таковы:
.
Пусть вероятности появления этих знаков
в сообщениях таковы: ,
, ,
, ,
, ,
, и
и .
Расположим эти знаки в таблице в порядке
убывания вероятностей.
.
Расположим эти знаки в таблице в порядке
убывания вероятностей.
Разделим
знаки на две группы так, чтобы суммы
вероятностей в каждой из этих двух групп
были бы приблизительно равными. При
этом в 1-ю группу попадут
 и
и ,
а остальные – во 2-ю группу. Знакам
,
а остальные – во 2-ю группу. Знакам первой группы присвоим первый слева
разряд их кодов «0», а первым слева
разрядом кодов символов второй группы
пусть будет «1».
первой группы присвоим первый слева
разряд их кодов «0», а первым слева
разрядом кодов символов второй группы
пусть будет «1».
Продолжим
деление каждой из получающихся групп
на подгруппы по той же схеме, то есть
так, чтобы суммы вероятностей на каждом
шаге в обеих подгруппах делимой группы
были бы возможно более близкими. Таким
образом будем получать по одному
следующие разряды кодов символов
 .
Эти следующие разряды будем приписывать
справа к уже имеющимся.
.
Эти следующие разряды будем приписывать
справа к уже имеющимся.
Вся эта процедура может быть схематически изображена в табл 7.
Табл. 7. Построение кода Шеннона-Фано
|
Знак |
|
Разряды кода | ||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||
|
| ||||||







Видно, что построенные коды знаков
 удовлетворяют условию Фано, следовательно,
такое кодирование является префиксным.
удовлетворяют условию Фано, следовательно,
такое кодирование является префиксным.
Найдем среднюю длину полученного кода по формуле
 ,
,
где
 – число разрядов (символов) в коде,
соответсвующем символу
– число разрядов (символов) в коде,
соответсвующем символу .
.
Из таблицы видно, что
 ,
, ,
, .
.
Таким образом, получаем:
Таким образом, для кодирования одного
символа
 первичного алфавита
первичного алфавита потребовалось в среднем 2.45 символов
вторичного (двоичного) алфавита.
потребовалось в среднем 2.45 символов
вторичного (двоичного) алфавита.
Определим среднее количество информации, приходящееся на знак первичного алфавита в первом приближении (с учетом различной вероятности появления этих знаков в сообщениях). Применим формулу Шеннона:
 .
.
Найдем избыточность полученного двоичного кода:
 ,
,
то есть избыточность – около 2.5.
Выясним, является ли полученный код оптимальным. Нулей в полученных кодах – 6 штук, а единиц – 11 штук. Таким образом, вероятности появления 0 и 1 далеко не одинаковы. Следовательно, полученный код нельзя считать оптимальным.
На тестах для подготовки к ЕГЭ по информатике встречаются задачи на применение условия Фано. Материала в учебниках не нашел. Заходим в Википедию.
Условие Фано (англ. Fano condition, в честь Роберта Фано) - в теории кодирования необходимое условие построения самотерминирующегося кода (в другой терминологии, префиксного кода). Обычная формулировка этого условия выглядит так:
Никакое кодовое слово не может быть началом другого кодового слова.
Более «математическая» формулировка:
Если в код входит слово a, то для любой непустой строки b слова ab в коде не существует.
Алгоритм Шеннона - Фано - один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Роберт Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся - кодом большей длины. Коды Шеннона - Фано префиксные, то есть никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Основные сведения
Кодирование Шеннона- Фано(англ. coding) - алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана, алгоритм Шеннона - Фано использует избыточность сообщения, заключённую в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов - более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
1. Основные понятия
Закодировать текст – значит сопоставить ему другой текст. Кодирование применяется при передаче данных – для того, чтобы зашифровать текст от посторонних, чтобы сделать передачу данных более надежной, потому что канал передачи данных может передавать только ограниченный набор символов (например, - только два символа, 0 и 1) и по другим причинам.
При кодировании заранее определяют алфавит, в котором записаны исходные тексты (исходный алфавит) и алфавит, в котором записаны закодированные тексты (коды), этот алфавит называется кодовым алфавитом. В качестве кодового алфавита часто используют двоичный алфавит, состоящий из двух символов (битов) 0 и 1. Слова в двоичном алфавите иногда называют битовыми последовательностями.
2. Побуквенное кодирование
Наиболее простой способ кодирования – побуквенный. При побуквенном кодировании каждому символу из исходного алфавита сопоставляется кодовое слово – слово в кодовом алфавите. Иногда вместо «кодовое слово буквы» говорят просто «код буквы». При побуквенном кодировании текста коды всех символов записываются подряд, без разделителей.
Пример 1. Исходный алфавит – алфавит русских букв, строчные и прописные буквы не различаются. Размер алфавита – 33 символа.
Кодовый алфавит – алфавит десятичных цифр. Размер алфавита - 10 символов.
Применяется побуквенное кодирование по следующему правилу: буква кодируется ее номером в алфавите: код буквы А – 1; буквы Я – 33 и т.д.
Тогда код слова АББА – это 1221.
Внимание: Последовательность 1221 может означать не только АББА, но и КУ (К – 12-я буква в алфавите, а У – 21-я буква). Про такой код говорят, что он НЕ допускает однозначного декодирования
Пример 2. Исходный и кодовый алфавиты – те же, что в примере 1. Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А – 01, код Б – 02 и т.д.
В этом случае кодом текста АББА будет 01020201. И расшифровать этот код можно только одним способом. Для расшифровки достаточно разбить кодовый текст 01020201 на двойки: 01 02 02 01 и для каждой двойки определить соответствующую ей букву.
Такой способ кодирования называется равномерным. Равномерное кодирование всегда допускает однозначное декодирование.
Далее рассматривается только побуквенное кодирование
3. Неравномерное кодирование
Равномерное кодирование удобно для декодирования. Однако часто применяют и неравномерные коды, т.е. коды с различной длиной кодовых слов. Это полезно, когда в исходном тексте разные буквы встречаются с разной частотой. Тогда часто встречающиеся символы стоит кодировать более короткими словами, а редкие – более длинными. Из примера 1 видно, что (в отличие от равномерных кодов!) не все неравномерные коды допускают однозначное декодирование.
Есть простое условие, при выполнении которого неравномерный код допускает однозначное декодирование.
Код называется префиксным, если в нем нет ни одного кодового слова, которое было бы началом (по-научному, - префиксом) другого кодового слова.
Но я хочу продемонстрировать как можно автоматизировать данный процесс.
Видеоролик выложу в интернет
Приведу пример из подготовки к ЕГЭ по информатике (фирма 1С - материалы Центра Сертифицированного Обучения):
Для кодирования некоторой последовательности, состоящей из букв С, Т, Р, О, К и А, используется неравномерный двоичный код, удовлетворяющий условию Фано, и следовательно, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: С - 000, Т - 001, Р - 010, О - 100, К - 011, А - 11. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по прежнему удовлетворял условию Фано? Коды остальных букв меняться не должны.
Выберите правильный вариант ответа.
Варианты ответов:
1) для буквы Р - 01
2) для буквы О - 10
3) для буквы А - 1
4) это невозможно
Правильный вариант - 2
Решение:
Вариант 1) не подходит - условие Фано будет нарушено для букв Р и К
Вариант 2) подходит - слово 10 не является началом кодовых слов для других букв
Вариант 3) не подходит - условие Фано будет нарушено для букв А и О
Вариант 4) не подходит - см. вариант 2)
Теперь посмотрим, что выдаст программа для автоматизированного решения подобных задач и контроля знаний.
В задании не задана частотность или вероятность появления букв, поэтому в программе примем ее равной 0,01 для всех букв.
Вероятности:
0.01, 0.01, 0.01, 0.01, 0.01, 0.01
Значения:
C, T, P, O, K, A
Результат:
C 000
T 001
P 01
O 100
K 101
A 11
Из решения видно, вариантов решения может быть несколько, но все они отвечают условию Фано.
Полагаю, что подобные программы будут полезны для контроля знаний, а включение подобной функции в язык программирования усилит возможности языка, поэтому включаю данную функцию в язык SmartMath. Программа сама определяет количество символов для анализа, сортирует их в зависимости от частотности и присваивает коды согласно условия Фано. Преимущество автоматизации в создании кода при выполнении условия Фано в том, что можно быстро создавать решения для любой последовательности.
Смотрите ссылку.