Сжатие базы данных и журнала транзакций в Microsoft SQL Server. Что такое сжатие в Microsoft SQL Server? Увеличение размера БД
Давайте забудем о свертке БД? Файловые группы и секции таблиц SQL, сжатие таблиц SQL. October 10th, 2011
В современных условиях очень странно бывает иногда слышать "нам нужно свернуть БД 1С - её объём превышает 50 ГБ". Если бы такое собирались сделать администраторы систем SAP R3 или Oracle e Business Suite или даже MS Dynamics Ax их бы наверное уволили. Тем не менее, для 1С это является "стандартной практикой".
Для файловых версий история тянется ещё с версии 1С 7.7 с ограничением в 2ГБ на размер базы. Сейчас ограничение 2ГБ уже только на размер таблицы, размер файла уже может получиться очень и очень не маленьким. Правда если база у вас выросла до такого размера, то наверное туда активно вносились данные - может нужно задуматься о клиент-сервере?
Собственно целью данной статьи является "отговорить" от выполнения свертки БД пользователей клиент-серверного варианта 1С, за счет использования несколько более "продвинутых" технологий.
Итоговая цифра получается 30-40 т. минимум против 20-25 в случае покупки жесткого диска, и получения 500 ГБ дополнительного места
Поэтому появляются продукты вроде http://infostart.ru:8080/public/78934/
Хорошие наверное продукты, и цели свои выполняют. Вот только меняется структура таблиц от версии к версии платформы. 1С нам об этом не раз говорили. Появился разделитель данных в 14-ом релизе и всё... скорее всего эта обработка для 14 релиза уже не подойдёт. Да и страшно как-то, не говоря уже о нарушении лицензионного соглашения.
И даже после этого найдутся пользователи которым "вдруг неожиданно понадобились" стертые данные, которые "как раз хотели поправить" каку-то циферку, которая "не влияет на последовательнсти" в документе закрытого периода. А хуже если выяснится что кто-то эти документы смотрел постоянно для каких-то только ему ведомых целей. Конечно это всё лишь ошибки в методике работы, но тем не менее недовольство пользователей будет.
Открываем Management Studio в списке баз выбираем нужную, открываем её свойства.
- Переходим на вкладку "Файловые группы" как показано на рисунке, и добавляем ещё одну файловую группу (на примере она названа SECONDARY)
- Переходим на вкладку "Файлы" и добавляем новый файл, для которого выбираем созданную файловую группу. Этот файл МОЖНО РАСПОЛОЖИТЬ НА ДРУГОМ ДИСКЕ
-
Теперь используя обработку к примеру:http://infostart.ru/public/78049/ определяем какие таблицы мы можем смело "пожертвовать" на более медленный (ну или наоборот всё на медленный, остальные - на более быстрый) носитель. Правило 80/20 здесь действует. 80% операций проводятся с 20% данными, так что думайте какие таблички вам нужны оперативно, а какие не очень. "Хранилище дополнительной информации", документы ввода начальных остатков, документы которые уже не используете сразу определяйте как те которые можно перенести в "медленную" файловую группу.
Выбираем таблицу которую нужно перенести в другую файловую группу - выбираем меню изменения таблицы (проект) и в свойствах меняем файловую группу:
индексы таблицы при этом тоже переносятся в данную файловую группу.
Достаточно удобный механизм распределения таблиц по дисковым массивом разной скорости. Лицензионному соглашению это не противоречит, т.к. в решении мы не используем доступ к данным и к информационной базе средствами отличными от платформы 1С. Мы лишь организуем хранение этих данных удобным образом.
EXEC sp_MSforeachtable "ALTER INDEX ALL ON ? REBUILD WITH (DATA_COMPRESSION = PAGE)" GO
После выполнения этого кода все таблицы в БД будут сжаты. Очевидно, что можно сжимать и таблицы по отдельности... это как бы на ваш выбор. Что даёт сжатие?
- Экономия дискового пространства
- Снижение нагрузки на дисковую подсистему
Что расходуется? - процессорное время.
Так что если у вас процессор загружен всё время на 70% и выше - сжатие вам использовать нельзя. Если 20-30% загрузка процессора, и при этом очередь к диску вырастает до 3-4... то сжатие таблиц - как раз "лекарство" для вас. Подробнее про сжатие таблиц БД - http://msdn.microsoft.com/ru-ru/library/cc280449(v=sql.100).aspx
Важное замечание - функция сжатия таблиц доступна только для обладателей версии Enterprise SQL Server
г) Секционирование таблиц БД
Разделить таблицы на разные файловые группы конечно хорошо... но вы скажете что есть тут парочка таблиц... которые тянутся с 2005 года... и уже занимают с десяток гигабайт.. вот бы в них все данные да отдельный диск положить, а текущие оставить.
Вы не поверите, но и это тоже возможно, хотя и не очень просто:
Создаём функуцию секционирования по дате:
create partition function YearSection(datetime)
as range right for values ("20110101");
Всё что до 2011 года будет попадать в одну секцию, всё что после - в другую.
Создаём схему секционирования
create partition scheme YearScheme
as partition YearSection to (SECONDARY, PRIMARY);
Этим говорим, что все данные до 11 года будут попадать в файловую группу "Secondary" а после - в "Primary"
Теперь осталось таблицу перестроить с разделением на секции. Для этого проще всего воспользоваться уже management studio, потому как процесс не простой. Вам нужно перестроить кластерный индекс для таблицы (который по сути и является самой таблицей), выбрав для индекса созданную схему секционирования:
На рисунке вы видите что выбор не доступен - всё правильно, секционирование таблиц возможно только в версии Enterprise MS SQL Server . Кластерный индекс отличить легко - картинка с круглыми скобками. Для РН и всех объектов 1С он создаётся. Для РН кластерный индекс по периоду есть всегда. Для документов и справочников хорошо бы конечно создать другой, который включает реквизит по которому будет секционирование... но это уже будет являться нарушением лицензионного соглашения.
2) Низкая производительность выполнения запросов.
Все действия, описанные выше не должны повлиять на скорость выполнения основных запросов. Более того, использование файловых групп и секций таблиц позволит вам разместить наиболее часто используемые данные на быстрых дисковых массивах, позволит поменять конфигурацию дисковых массивов, использовать небольшие по размеру i/o accelerator. Таким образом скорость выполнение запросов только повысится. А сжатие таблиц позволит вам дополнительно разгрузить дисковую подсистему, если она являлась узким местом. А вообще если говорить о скорости выполнения запросов, то анализ их планов выполнения, оптимизация запросов для грамотного использования индексов даст намного более существенный прирост производительности, чем все "ухищрения" на уровне MS SQL.
Большой объём "ненужных данных" которые мешают работе пользователей
Но для этого нужно не сворачивать базу, а проделать следующее:
а) Объяснить всем как пользоваться отборами, как они сохраняются, как пользоваться интервалами журнала, как они сохраняются
б) Пометить на удаление ненужные данные если они не несут никакой смысловой нагрузки (контрагентов и номенклатуру, с которыми больш не работаете) - этим вы принесёте пользователям больше пользы чем сверткой. В случае наличия ресурсов настроить автоматическую пометку на удаление неиспользуемых объектов и сделать отбор по умолчанию в программном коде для того чтобы не отображались по умолчанию не нужные пользователям объекты - помеченные на удаление
в) Настроить другие полезные "отборы по умолчанию" - например чтобы каждый менеджер по умолчанию видел только свои документы. А если хочет посмотреть документы "товарища" - нужно отключать отбор.
По всем реквизитам, которые участвуют в отборе не забывайте ставить признак "Индексировать с доп. упорядочиванием" - тогда на производительности системы такие "удобства" не скажутся.
Сжатие данных доступно только в SQL Server Enterprise Edition, но начиная с SQL Server 2016 SP1, его добавили во все редакции. Нет так просто ответить на вопрос «будет ли польза от использования сжатия данных в конкретном случае или нет». Предлагаю рассмотреть это более детально.
Плюсы
Сжатие данных позволяет хранить больше строк на одной странице, что в конечном счёте приводит к экономии места. Кроме экономии дискового пространства (не только для самой базы данных, но так же и для backup), мы получает экономию памяти, так как даже в памяти данные хранятся в сжатом виде.
Наиболее полезным будет использовать сжатие данных на так называемых «холодных данных», которые редко используются и, обычно, не хранятся в памяти, а читаются с диска.
Минусы
Сжаты могут быть только данные, которые хранятся в строках (in-row). Это означает, что длинные строки (более 8 Кб) и LOB данные (большие) не могут быть сжаты, так как они хранятся не в строках, а помещаются в специальное хранилище, а в строке остаётся ссылка на них.
Если применение сжатия к страницам не экономит пространство, то такие страницы будут храниться в без применения сжатия.
Для каждого доступа к сжатым данным требуются дополнительные ресурсы CPU. Данные находятся в сжатом виде не только на диске, но и в памяти, по этой причине, при каждом обращении к ним, требуется распаковка. Не следует применять сжатие к очень горячим данным, так как обращение к ним будет замедляться из-за дополнительного этапа распаковки.
Принцип работы простыми словами
Сжатие на уровне строк: переводит фиксированный тип данных в переменный. Например, int, обычно занимает фиксированно 4 байта, но если вы храните 123, то это значение может поместиться в 1 байт + метаданные на хранение переменной длины.
Сжатие на уровне страницы: первым делом применяет сжатие на уровне строк, затем страница сравнивается с некоторым словарём, применяются алгоритмы, которые находят повторяющиеся последовательности. Это позволяет сжать данные значительно сильнее.
Применить сжатие или нет — это большой вопрос
- Рассмотрите большие таблицы. Вам не следует рассматривать сотни маленьких таблиц, сжатие которых не принесёт пользы.
- Убедитесь, что объекты не фрагментированы перед применение компрессии (используйте sys.dm_db_index_physical_stats ). Фрагментация может привести с сильным погрешностям сжатия и вы не получите достаточного выигрыша
- Проверьте как много данных выбранного объекта находится в памяти (используйте sys.dm_os_buffer_descriptors ). Если большая часть объекта находится в памяти, то вы не получите выигрыша от применения сжатия, так как они могут быть горячими. Но если такие данные редко используются, то вы всё равно можете получить преимущество от сжатия, сжатые данные будут заниматься меньше объёма памяти.
- Посмотреть как часто используются объекты памяти можно с помощью sys.dm_db_index_operational_stats . Чем чаще объекты используются, тем больше CPU ресурсов будет затрачено.
- Проверьте возможный процент сжатия с помощью sys.sp_estimate_data_compression_savings . Если выигрыш незначительный, не применяйте сжатие, в противном случае вы потратите ваши CPU ресурсы в пустую. Выигрыш от сжатия на уровне строк должен быть хотя 15%, для сжатия на уровне страниц не менее 30%.
- Рассмотрите использование колоночных индексов. Сжатие уровня страниц, обычно, даёт уровень сжатия 50%, но колоночные индексы сжимают значительно сильнее (сжатие доходит до 10х). Колоночные индексы существенно отличаются от обычных, поэтому не применяйте их без изучение принципа их работы.
Вывод
Начиная с SQL Server 2016 сжатие доступно во всех редакциях, что позволяет использовать его в любых приложениях. Кроме сжатия, в SQL Server 2016, стали доступны и другие функции Enterprise Edition — это замечательный подарок от Microsoft.
Cжатие данных в SQL Server 2008.
Недавно мне пришлось выполнять миграцию своего хранилища данных с SQL Server 2005 на SQL Server 2008. Как известно, одним из новшеств SQL Server 2008 является сжатие данных. Эта возможность призвана увеличить производительность базы данных за счет сжатия данных и индексов в таблицах и индексированных представлениях и, как следствие, уменьшения операций ввода-вывода. Также, благодаря сжатию, может существенно уменьшится размер базы, что облегчает администрирование и управление. Все это звучало заманчиво, и я решил использовать эту возможность.
Причиной, побудившей меня более внимательно разобраться с данной функциональностью, и в конечном итоге написать эту статью, стало получение совершенно иного результата чем ожидалось:)
Я решил провести сжатие трех самых крупных таблиц фактов, представляющих собой структуры, с максимально компактными, насколько это возможно, столбцами, ссылающимися на справочники-измерения и содержащими ряд показателей, которые агрегируются в отчетах. Ниже будет приведена типичная структура таблицы фактов и типичный запрос к этой таблице, в упрощенном виде.
Но к моему удивлению, после сжатия, я не только не получил прироста производительности, но наоборот - выполнение запросов замедлилось. В некоторых случаях производительность осталась на прежнем уровне.
Было решено исследовать эффект от сжатия данных и провести тестирование, чтобы ответить на вопрос о падении производительности.
Подготовка теста.
Итак, есть таблица, назовем ее ProductMMR содержащая некие факты в нескольких разрезах.
Вот ее структура:
Склад
Товар
Дата
Тип склада
Количество
Исходный размер таблицы - 16 ГБ, индексов - 18 ГБ (я воспользовался системной ХП sp_spaceused для определения размеров данных и индексов).
Теперь самое время решить по каким критериям будем оценивать эффективность сжатия.
Поскольку практически каждого разработчика или администратора волнует производительность его серверов и приложений, очевидно, что главным критерием оценки эффективности сжатия будет время, затраченное на выполнение запросов, количество операций ввода-вывода, количество затраченного процессорного времени. Также будет принято во внимание освободившееся дисковое пространство в результате сжатия.
Вот тестовый запрос на выборку к данной таблице:
SET STATISTICS TIME ON -- для измерения времени выполнения запроса
SET STATISTICS IO ON -- для измерения логических и физических операций ввода-вывода
GO
SELECT
fact.DateID,
fact.StockID,
SUM(fact.Qty) AS Qty
FROM fact.ProductMMR fact
WHERE (fact.DateID BETWEEN @DateIDBegin AND @DateIDEnd)
GROUP BY fact.DateID, fact.StockID
Был задан временной промежуток 30 дней (в таблице фактов это соответствует более 150 млн. записей).
Определение стратегии сжатия и его реализация.
Подробно про реализацию сжатия можно почитать в MSDN. Там же описана реализация сжатия для страниц и для строк . Эффект от сжатия зависит от данных в таблице - насколько много там повторяющихся значений и каков тип данных.
Теперь перейдем к реализации сжатия, предварительно определив его стратегию.
Sunil Agarwal в своем блоге приводит ряд рекомендаций по этому поводу, позволю себе их обобщить и привести здесь:
1. Не имеет смысла сжимать данные или индексы имеющие малый размер. Если таблица занимает 10 страниц, и будет сжата до одной, то это не принесет выгоды в данном случае. Необходимо помнить о том, что сжатые данные должны быть распакованы каждый раз, когда к ним осуществляется доступ. Перед применением сжатия, вы должны оценить текущий размер таблицы/индекса и прогнозируемый размер после сжатия.
2. Если таблица интенсивно используется операторами DML и SELECT, то в результате сжатия вы можете получить чрезмерную нагрузку на процессоры в результате распаковки при каждом обращении к этим данным. В этом случае необходимо особо тщательно подойти к вопросу целесообразности сжатия таблицы/индекса.
3. Если экономия от сжатия невысока, тогда сжатие проводить не рекомендуется. Бывают такие случаи, когда размер сжатых данных оказывается больше несжатых. Это говорит о том, что в таблице используются наиболее компактные типы данных.
4. Если у вас типичное OLTP-приложение, в общем случае вам следует выбирать сжатие типа ROW. Этот тип сжатия менее затратный с точки зрения распаковки данных. Однако, как правило, сжатие типа PAGE более эффективно, в плане потенциального свободного пространства.
Оценить выгоду от сжатия можно либо в мастере, либо при помощи хранимой процедуры sp_estimate_data_compression_savings.
В моем случае я получил такие результаты:
Таблица 1.
Эффективность сжатия данных.
Тип сжатия | Размер до сжатия | Размер после сжатия | % сжатия |
ROW | 33,4 ГБ | 22,7 ГБ | 32 % |
PAGE | 33,4 ГБ | 18,3 ГБ | 45 % |
Как видно из таблицы, получить эффект от сжатия данных можно. Хотя в данном случае, это не самый хороший показатель, во многих случаях данные сжимаются на 70-80%.
Во многих случаях коэффициент сжатия будет больше, а в некоторых - намного больше, чем получился у меня в этом тесте. Все зависит от типов данных и от того, насколько много повторяющихся данных в ваших таблицах.
Видно, что в тестовой таблице сжатие на уровне строк будет не столь эффективным, как сжатие страниц. Необходимо принять во внимание, что сжатие PAGE является надмножеством сжатия ROW.
Реализовать сжатие таблицы типа PAGE/ROW можно через мастер сжатия, генерирующего подобный код:
ALTER TABLE . REBUILD PARTITION = ALL
WITH
(DATA_COMPRESSION = ROW
)
Применить сжатие типа PAGE можно, применив параметр DATA_COMPRESSION = PAGE.
Указав DATA_COMPRESSION = NONE можно отменить сжатие данных.
Я не буду приводить здесь синтаксис сжатия индексов и партиций, интересующийся без труда найдет их в BOL.
Надо помнить, что перед включением или отключением сжатия строки или страницы, необходимо столько же места на диске, как и для создания или перестройки индекса.
Результаты тестирования.
Итак, до и после сжатия по типу PAGE был выполнен тестовый запрос.
Вот его результаты, на «разогретом» кэше:
Таблица 2.
Результаты теста № 1*.
Тип сжатия | Время выполнения запроса(мс) | Операций логического чтения** | Затраченное процессорное время (мс) |
Без сжатия | 26 147 | 1 419 113 | 308 736 |
Сжатие PAGE | 41 104 | 709 360 | 486 453 |
*Запрос выполнялся на сервере с 12 ядрами и 32 Гб ОЗУ, дисковая подсистема 10 RAID.
** Показаны только операции логического чтения, т.к. физического чтения не было - данные находились в кэше.
Увидев эти результаты, можно удивиться - ведь операций логического чтения на сжатых данных было произведено в два раза меньше, но время выполнения запроса оказалось на 36 % больше. А все дело видимо в том, что хоть операций чтения меньше и читается все из памяти, но велики накладные расходы на распаковку данных. Ведь распаковывается не страница целиком, а каждая запись по отдельности.
Можно предположить, что если данные будут незакэшированы, то в этом случае можно добиться прироста производительности, за счет уменьшения количества дорогостоящих операций физического чтения, в случае сжатых данных.
Поэтому было решено провести еще один цикл тестов, но уже на холодном кэше.
Был выполнен то же самый тестовый запрос, но предварительно был очищен кэш процедур и буфер, при помощи команд DBCC FREEPROCCACHE и DBCC DROPCLEANBUFFERS .
Вот результаты тестового запроса до и после сжатия, на «холодном» кэше:
1 419 105
1 420 868
235 266
Сжатие данных PAGE
48 887
707 495
710 105
416 689
Вот эти результаты подтверждают ранее высказанное предположение. Как видно, время выполнения отличается на 12 %, вместо 36 % из первого теста.
Статистика по операциям логического чтения такая же, но в данном тесте присутствует физическое чтение, которое существенно сказывается на производительности запроса (сравните время выполнения с первым тестом). И, судя по всему, сжатие данных будет давать положительный эффект в плане производительности тогда, когда будут выполняться запросы к редко используемым, большим массивам данных, сжатие которых позволит сэкономить на операциях физического чтения , по сравнению с которыми распаковка данных из буферного пула менее дорогостоящая операция. Хорошим примером может быть сжатие партиций с данными за самые ранние периоды в хранилище или сжатие других больших редко используемых таблиц. Напомню, что сжимать данные можно как на уровне таблиц, так и на уровне партиций и индексов. Причем можно комбинировать типы сжатия.
Мне удалось добиться того, что на тестовой таблице выборка сжатых данных, за больший период, стала выполняться примерно на одном уровне, с выборкой несжатых данных за тот же период, т.е. чем больше массив данных, к которым обращался запрос, тем положительный эффект от сжатия был больше, т.к. серверу сначала приходилось обращаться за большим объемом данных к дисковой системе а не буферному пулу.
Но самая главная причина того, что в моем случае упала производительность запросов - это относительно невысокий коэффициент сжатия, менее 50 %. Я провел еще несколько тестов и обнаружил, что на тех таблицах, которые сжимались на 60-75 %, производительность запросов увеличивалась по сравнению с несжатыми таблицами.
Очевидно, что чем выше процент сжатия, тем сильнее это скажется на приросте производительности.
В любом случае, прежде чем приступать к этой операции необходимо провести тестирование и оценить эффект от сжатия данных.
Сергей Харыбин, MCTS SQL Server.
Ну вот я и попробовал сжатие на реальной системе и на реальных базах данных. Пару слов о том, что это такое и переходим к делу. Компрессия данных появилась в SQL Server 2008 и со стороны её можно представить в виде айсберга. На верхушке которого - уменьшение занимаемого дискового пространства, а скрыто от глаз ещё более интересное преимущество - снижение нагрузки на ввод/вывод за счёт меньшего количества читаемых данных. Ну и конечно же, не могу обойти стороной один не очень хороший момент - увеличение нагрузки на CPU, но без этого никак. Более того, сам алгоритм сжатия данных не преследует цель максимально зажать данные, а призван соблюдать разумный баланс между процентом сжатия данных и затратами на упаковку/распаковку данных. Сжатие работает в двух режимах: Row Compression и Page Compression . И в своём посте я расскажу о том как и насколько я зажал данные реальных баз и как это сказалось на работе приложений.
Компрессия данных, для своей настройки требует минимум телодвижений. Включить компрессию для таблицы можно следующим образом:
ALTER TABLE Test REBUILD WITH (DATA_COMPRESSION = PAGE);
GO
В этом случае будет сжат либо кластерный индекс таблицы (если он есть) либо данные таблицы хранящиеся в куче. Здесь нужно помнить, что некластерные индексы не будут сжаты в этом случае. А при использовании индексов с конструкцией INCLUDE это может быть довольно значительный объём данных. Более подробно о сжатии таблиц, индексов и различных аспектов, связанных со сжатием можно почитать здесь - Создание сжатых таблиц и индексов . Я же хочу показать свой вариант сжатия всей базы данных одним махом Для этого я использую недокументированную процедуру sp_MSforeachtable (вместо символа вопроса хранимка подставляет имя таблицы, таким образом код выполняется для всех таблиц в базе данных):
EXEC sp_MSforeachtable "ALTER INDEX ALL ON ? REBUILD WITH (DATA_COMPRESSION = PAGE)"
GO
Таким образом мы убиваем двух зайцев - кластерные и некластерные индексы , при этом код получился довольно элегантным. Единственным исключением такого кода будет то, что таблицы без кластерного индекса останутся не сжатыми.
Посмотреть фактический объём данных базы можно при помощи следующего скрипта:
CREATE TABLE #t (name SYSNAME, rows CHAR (11), reserved VARCHAR (18),
data VARCHAR (18), index_size VARCHAR (18), unused VARCHAR (18))EXEC sp_msforeachtable "INSERT INTO #t EXEC sp_spaceused " "?" ""
SELECT SUM (CONVERT (INT , SUBSTRING (data , 1, LEN(data )-3))) FROM #t
DROP TABLE #t
Запустив этот скрипт до и после компрессии, можно посмотреть эффект, произведённый сжатием. На моих базах (размером от 10-и до 50 Гб) объём данных уменьшился примерно на одну четвёртую. Также вы может сделать замеры показателей использования CPU и памяти в моменты нагрузки системы и сравнить их с показателями до включения сжатия. Напоследок хочу сказать, что недостатков включения компрессии я не почувствовал, только преимущества . Система работает стабильно уже на протяжении нескольких недель, что не может не радовать Но в то же время, на нашем сервере, на котором стоит сиквел, процессор используется далеко не по полной. И я бы не рекомендовал рисковать и включать компрессию на системах с дефицитом процессорного времени.
Многие администраторы Microsoft SQL Server сталкивались с проблемой значительного увеличения физического размера базы данных и файлов журнала транзакций и, конечно же, им хотелось бы каким-то образом уменьшить этот размер, для того чтобы не предпринимать какие-либо действия, связанные с увеличением свободного пространства на жестком диске. Способ уменьшить физический размер базы данных и файлов журнала транзакций в SQL сервере есть – это сжатие .
Что такое сжатие в Microsoft SQL Server?
Сжатие - это процесс удаления неиспользуемого пространства в файлах базы данных и журнала транзакций.
Физический размер файлов базы данных со временем растет, это связанно с добавлением данных, но при их удалении физический размер файлов остается неизменным, однако в данных файлах появляется логическое неиспользуемое пространство, которое и можно удалить.
Наибольший эффект от сжатия достигается тогда, когда операция сжатия выполняется после операции удаления таблиц из БД или удаления данных из таблиц.
Следует отличать процедуру сжатия журнала транзакций от процедуры усечения журнала транзакций. Сжатие - это уменьшение физического размера журнала за счет удаления неиспользуемого пространства, а усечение – это освобождение места в логическом журнале для повторного использования (т.е. образуется неиспользуемое пространство ) журналом транзакций при этом размер физического файла не уменьшается.
Усечение журнала транзакций происходит автоматически:
- В простой модели восстановления - после достижения контрольной точки, которая может возникнуть, например, после создания BACKUP базы данных, при явном выполнении инструкции CHECKPOINT, или тогда когда размер логического журнала транзакций заполняется на 70 процентов, во всех этих случаях происходит автоматическая очистка неактивной части журнала, т.е. его усечение;
- В модели полного восстановления или в модели восстановления с неполным протоколированием - после создания резервной копии журнала при условии, что с момента создания последней резервной копии журнала была достигнута контрольная точка.
Если Вы используете модель полного восстановления или в модель восстановления с неполным протоколированием и у Вас файлы журнала транзакций слишком велики, то скорей всего Вы достаточно долго не делали BACKUP (резервную копию ) журнала транзакций. В данном случае Вам необходимо сделать сначала BACKUP журнала транзакций, а затем выполнить сжатие журнала транзакций, которое мы как раз и рассмотрим чуть ниже.
Также возможно размер файлов журнала транзакций слишком большой (как при простой, так и при полной модели восстановления ) за счет задержки процедуры усечения, т.е. размер журнала, состоит в основном из активной части журнала, а активную часть усечь нельзя, поэтому физический размер журнала растет. На задержку процедуры усечения влияют такие факторы как: активные длительные транзакции, некоторые сценарии отображения зеркальных баз данных и журнала транзакций, некоторые сценарии при репликации транзакций и журнала транзакций, а также усечение журнала невозможно во время операций резервного копирования и восстановления данных. В данном случае Вам нужно устранить причины задержки, затем сделать усечение (т.е. например, для полной модели восстановления BACKUP журнала ), а затем сжатие до приемлемых размеров.
Обычно если на постоянной основе с определенной периодичностью создаются резервные копии журнала транзакций или базы данных (при простой модели восстановления ), файлы журнала транзакций не растут, и не возникает переполнение журнала транзакций.
Как сжать базу данных в MS SQL Server?
Сжать файлы базы данных и журнала транзакций можно и с помощью графического интерфейса Management Studio и с помощью инструкций Transact-SQL: DBCC SHRINKDATABASE и DBCC SHRINKFILE . Также возможно настроить базу данных на автоматическое сжатие путем выставления параметра БД AUTO_SHRINK в значение ON.
Примечание! Сжатие базы данных я буду рассматривать на примере Microsoft SQL Server 2016 Express .
Сжимаем базу данных с помощью среды Management Studio
Запускаем Management Studio и в обозревателе объектов открываем объект «Базы данных ». Затем щелкаем правой кнопкой мыши по БД, которую необходимо сжать, далее выбираем «Задачи ->Сжать -> База данных (или Файлы, если, например, нужно сжать только журнал транзакций) ». Я для примера выбираю «База данных ».
В итоге у Вас откроется окно «Сжатие базы данных », в котором Вы, кстати, можете наблюдать размер базы данных, а также доступное свободное место, которое можно удалить (т.е. сжать ). Нажимаем «ОК ».
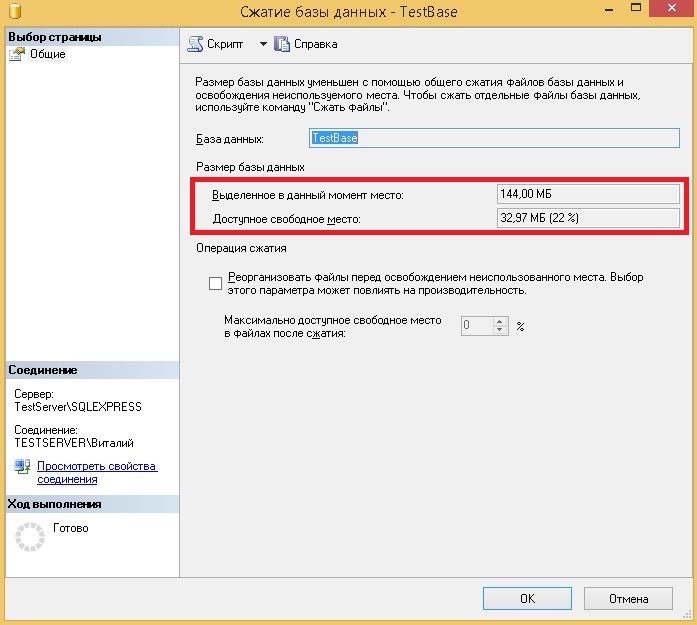
Через некоторое время, в зависимости от размера базы данных, сжатие будет завершено.
Сжимаем базу данных с помощью инструкций SHRINKDATABASE и SHRINKFILE
В MS SQL Server для выполнения сжатия файлов базы данных и журнала транзакций существуют две инструкции SHRINKDATABASE и SHRINKFILE.
- DBCC SHRINKDATABASE – это команда для сжатия базы данных;
- DBCC SHRINKFILE – с помощью данной команды можно выполнить сжатие некоторых файлов базы данных (например, только журнала транзакций ).
Для того чтобы выполнить сжатие БД (например, TestBase ) точно также как мы это сделали чуть ранее в Management Studio, выполните следующую инструкцию.
DBCC SHRINKDATABASE(N"TestBase")
SHRINKDATABASE имеет следующие параметры:
- database_name или database_id - имя или идентификатор базы данных, которую необходимо сжать. Если указать значение 0, то будет использоваться текущая база данных;
- target_percent – свободное пространство в процентах, которое должно остаться в базе данных после сжатия;
- NOTRUNCATE - сжимает данные в файлах с помощью перемещения распределенных страниц из конца файла на место нераспределенных страниц в начале файла. Если указан данный параметр, физический размер файла не изменяется;
- TRUNCATEONLY - освобождает все свободное пространство в конце файла операционной системе, но не перемещает страницы внутри файла. Файл данных сокращается только до последнего выделенного экстента. Если указан данный параметр, то параметр target_percent не обрабатывается;
- WITH NO_INFOMSGS - подавляет все информационные сообщения со степенями серьезности от 0 до 10.
Синтаксис SHRINKDATABASE
DBCC SHRINKDATABASE (database_name | database_id | 0 [ , target_percent ] [ , { NOTRUNCATE | TRUNCATEONLY } ]) [ WITH NO_INFOMSGS ]
Для того чтобы сжать только журнал транзакций можно использовать инструкцию SHRINKFILE , например.
DBCC SHRINKFILE (N"TestBase_log")
В данном случае мы осуществим сжатие файла журнала (TestBase_log – это название файла журнала транзакций ), до его начального значения, т.е. до значения по умолчанию. Для того чтобы сжать файл до определенного размера, укажите вторым параметром размер в мегабайтах. Например, следующей инструкцией мы уменьшим размер файла журнала транзакций до 5 мегабайт.
DBCC SHRINKFILE (N"TestBase_log" , 5)
Также необходимо учесть, что если Вы укажете размер меньше того, чем требуется для хранения данных в файле, то файл до этого размера сжат не будет. Например, допустим, если Вы указали 5 мегабайт, а для хранения данных в файле требуется 7 мегабайт, файл будет сжат только до 7 мегабайт.
SHRINKFILE также имеет параметры NOTRUNCATE и TRUNCATEONLY.
Синтаксис SHRINKFILE
DBCC SHRINKFILE ({ file_name | file_id } { [ , EMPTYFILE ] | [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ] }) [ WITH NO_INFOMSGS ]
- Операция сжатия базы данных может вызвать фрагментацию индексов и замедлить работу БД. Поэтому слишком часто не рекомендуется выполнять сжатие базы данных;
- Сжимать БД лучше до операции перестроения индексов, т.е. после сжатия запустите процедуру перестроения индексов;
- Параметр базы данных AUTO_SHRINK (автоматическое сжатие ) лучше не выставлять в значение ON, а оставлять по умолчанию, т.е. в OFF, если конечно у Вас нет на это достаточно серьезных оснований;
- Инструкция SHRINKDATABASE не позволяет уменьшить размер базы данных до размера, который меньше начального, т.е. минимального. Однако инструкция SHRINKFILE сделать это может (вторым параметром указываем размер меньше минимального ). Минимальный размер базы данных - это размер, который указан при создании базы данных или явно установленный операцией изменения размера БД, такой как DBCC SHRINKFILE или ALTER DATABASE. Например, если база данных была создана с размером 10 мегабайт, потом увеличилась до 100 мегабайт, ее можно сжать с помощью SHRINKDATABASE только до начальных 10 мегабайт, даже если все данные были удалены из базы данных;
- Сжимать файлы базы данных и журнала транзакций нельзя, когда идет процесс их резервирования. И наоборот, создавать резервные копии базы и журнала транзакций нельзя пока идет процесс их сжатия;
- Выполнение инструкции DBCC SHRINKDATABASE без указания параметра NOTRUNCATE или TRUNCATEONLY равносильно выполнению инструкции DBCC SHRINKDATABASE с параметром NOTRUNCATE после выполнения инструкции DBCC SHRINKDATABASE с параметром TRUNCATEONLY;
- В процессе сжатия базы данных пользователи могут работать в ней (т.е. переводить БД в однопользовательский режим не нужно );
- В любой момент времени Вы можете прервать процесс выполнения операций SHRINKDATABASE и SHRINKFILE, при этом вся выполненная работа сохраняется;
- Перед запуском процедуры сжатия проверьте, есть ли свободное пространство для удаления в файлах базы данных, т.е. можно ли вообще сжать файлы, выполнив следующий запрос (он покажет в мегабайтах, на сколько Вы можете уменьшить файлы БД ).

На этом у меня все, надеюсь, статья была Вам полезна, удачи!